
2014-06-02 »
Everyone's talking about Apple's new Swift language, which looks pretty clean. But the best part I've found so far is that it uses primarily "automated reference counting" (like python) instead of garbage collection. Finally, a language designer that's not crazy! Deterministic destructors! Deterministic memory usage! Statically compiled! Non-insane syntax?
It's like my birthday came early. Now if only they'd announce a new iOS colour scheme that doesn't make me want to gouge my eyes out.
2014-06-03 »
Oh boy, and me without my popcorn.
http://recode.net/2014/06/05/verizon-threatens-netflix-with-legal-action-over-congestion-message/

2014-06-04 »
The trouble with writing automated tests is not writing the actual tests. It's the stream of obvious bugs your tests find in the product while you are attempting to find non-obvious ones.
2014-06-05 »
An excellent move by Apple in the name of privacy controls:
https://twitter.com/fredericjacobs/status/475601665836744704
On the other hand, you'd perhaps want to be aware of it when designing wifi roaming controls into your APs. For example, I was thinking of using the RSSI of the Probe request as an indicator of which AP (when you have multiple APs on one SSID) should respond to a given probe. I think this feature would break that. Or maybe they do something fancy to us non-anonymous MAC addresses on the SSID you're already connected to.

2014-06-06 »
"Knowledge and productivity are like compound interest. Given two people of approximately the same ability and one person who works ten percent more than the other, the latter will more than twice outproduce the former. The more you know, the more you learn; the more you learn, the more you can do; the more you can do, the more the opportunity - it is very much like compound interest. I don't want to give you a rate, but it is a very high rate. Given two people with exactly the same ability, the one person who manages day in and day out to get in one more hour of thinking will be tremendously more productive over a lifetime."
– Richard Hamming
2014-06-07 »
If there had been an actual Atheros wifi chipset that was appropriate for use in our new TV box, I would now, in retrospect, describe the decision not to use it as a massive tactical error.
Since there was no such chipset (and I personally tried really hard to convince them to tell me there was one, even if it they had to lie, but they refused), I can only describe the universe as being generally a disappointment to me. Please try harder next time, universe.
(This is not really a slag against the alternate vendor we went with, who seems fine. It's just that we have to do everything twice, sigh.)
2014-06-08 »
Achievement unlocked: original SQLite developer emailed me to update my blog post about Unix file locking, to say there's yet another gotcha he just ran into.
http://apenwarr.ca/log/?m=201012#13
Funnily enough, I wrote that post based on reading how sqlite does locking. So the world has come full circle apparently.
2014-06-09 »
Netflix is really doing a great job here.
http://www.scribd.com/doc/228871116/Response-to-Demand-Letter
2014-06-10 »
Oh rats. I've been sort of laughing guiltily about all the "mobile first" stuff (in a "ha ha, I'm sure glad that's not me" sort of way). Then I realized that the reason I'm working on wifi is all those people who want all that fiber speed on their mobile devices.
There's no escape.
2014-06-11 »
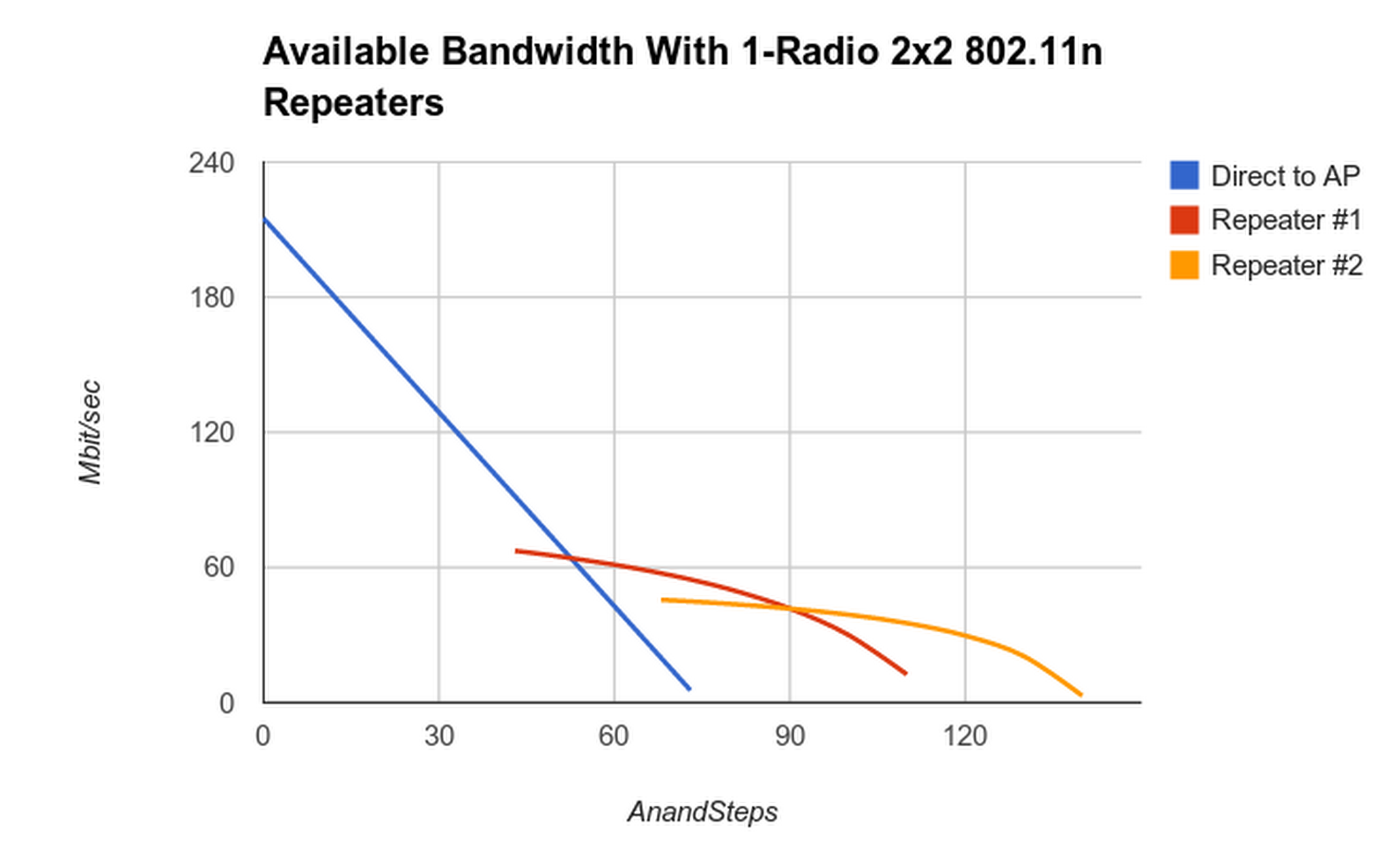
Calculations on the feasibility of 1-radio wifi repeaters
The short version is it's worse than expected.
The common wisdom about wifi repeaters is that they cut your bandwidth approximately in half with each hop. It turns out that's only true in the most optimistic case, where the repeater is so close to the upstream and downstream and it gets maximum wifi rates in each direction. But that never happens, because if you have signal strength that excellent, you didn't need a repeater.
What really happens is more like the diagram below. Let's say you're using 802.11n 2x2 40 MHz channels, with a marketing rate of 300 Mbit/sec (real-life throughput: 200 Mbit/sec). The blue line in the chart indicates the throughput you'd get if a station connected directly to the AP (no repeater) at distance x from the AP.
Now let's attach a repeater at about half the maximum range, ie. 100 Mbit/sec, x=45 AnandSteps or so in the chart. We then connect a station to the repeater. The red line corresponds to the overall speed you get (from the station to the AP) when your station is at location x. For x=45, your link to the repeater is about 200 Mbit/sec, so every bit you send upstream takes 1/200M seconds (station) + 1/100M seconds (repeater) = 1/66M seconds -> 66 Mbit/sec.
And you would never actually do that, because at x=45, you might as well talk to the AP directly and get your full 100 Mbit/sec. You'd want to use the repeater starting at x=50 or so (the crossover point between blue and red lines) where you get even less than 66 Mbit/sec.
Nowhere in this chart does anyone get even close to the "maximum throughput is cut in half" I was promised. And worse, note that if you let the client choose automatically between the AP and the repeater based on signal strength - as they typically do - then it will make the wrong decision between x=45 and x=50 or so, choosing the repeater because it's much closer even though it could get better results directly from the AP.
The orange line shows what happens when you add a second repeater into the chain. Interestingly, it doesn't feel all that much worse than one repeater.
That's the bad news. I'm still working on the good news.
2014-06-12 »
Sometimes a UX research team will do a lot of excellent research and present their conclusions, leading to a discussion of what you should do about the customer problems, and then you get a nice report with lots of well-justified suggestions for how to prioritize your upcoming work. And the suggestions will all be pretty relevant good ideas.
At that point, it will sometimes turn out that the suggestions based on the UX research are pretty much what you were going to do anyway. This is a good thing. Not a Eureka moment, obviously, but like all forms of science, corroborating existing results is valuable.
It also adds credibility when the UX researchers one day come back with results that are more controversial; then you know you should listen because they are right so often.
Contrast with UX teams that are constantly blowing your mind with their amazing discoveries and suggestions. That's not a good sign. It means either your UX research or your PM/Eng teams are horribly broken.
2014-06-14 »
In which someone publishes an actual scientific paper that says RSSI has different behaviour, in an idealized environment, depending whether you are North, South, East, or West of the transmitter.
http://www.cse.buffalo.edu/srds2009/F2DA/f2da09_RSSI_Parameswaran.pdf
This is why I did not pursue grad studies.
2014-06-15 »
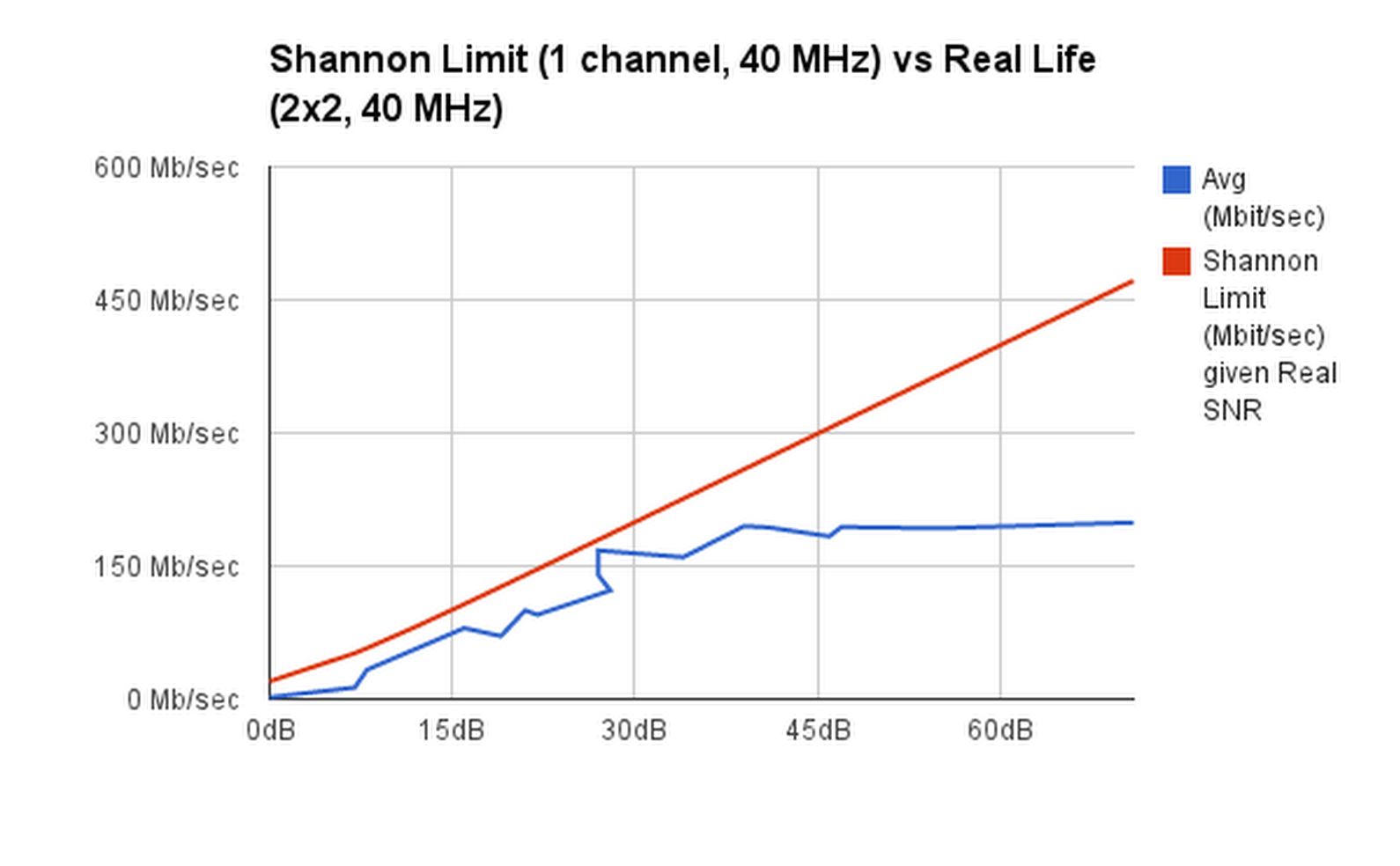
Having some trouble understanding how the Shannon Limit applies to modern wifi and especially, but not only, MIMO.
Here's a chart of my measurements of actual TCP throughput achieved at various distances between wifi client and access point. That's the blue line. The x axis is the signal to noise ratio. The line seems to be more or less straight (as predicted by theory) until the signal strength gets so high that 802.11n doesn't have a coding type that takes advantage of it, so it can't go any faster, and it flattens out.
The red line is the Shannon Limit, which defines the maximum capacity of a channel: http://en.wikipedia.org/wiki/Channel_capacity#Example_application
I used an example from here: http://www.ka9q.net/xmax_wifi.html to confirm my formula is not completely wrong. At 17.3 dB, it gives about 54 Mb/sec as expected for a 20 MHz channel. I'm using a 40 MHz channel with 802.11n, so I doubled all the values, and that's what you see here as the red line. (Trivia: the Shannon Limit is bandwidth*log(1+SNR), but note that it's the baseband bandwidth that seems to matter, and that's only half the modulated bandwidth. So you multiply by 10 for a 20 MHz channel, or 20 for a 40 MHz channel.)
As you can see (and as I confirmed more carefully), the red line has about the same slope as the blue line, other than the flattening out part. It's a bit higher, indicating that we don't quite hit the Shannon Limit (which is the theoretical maximum) but it seems pretty reasonable.
All good, right? Except... I didn't multiply by two for 2x2 MIMO. From what I've read, 2x2 MIMO should approximately double the limit, because you can treat it as two channels, and each channel has the same original Shannon Limit. When I multiply the red line by two, it of course looks completely wrong.
Moreover, you can't see it from this graph, but my original data tells me that for the blue line, all the values < 20 dB give up on 2x2 MIMO and switch down to SISO (1x1) modulations. I would expect to drop in half at that point, but as you can see, it doesn't. It just continues exactly the same linear progression. (Notably, in my actual table of MCS rates, it switches from a lower-rate 2x2 encoding (MCS11 -> 8+3) to a higher-rate 1x1 encoding (MCS4). So it's able to actually get more bits per channel when it uses fewer channels.
So okay, I'd even be willing to accept that 2x2 MIMO doesn't exceed the Shannon Limit as advertised, at least not indoors in an echo-ey environment with highly nonoptimal antenna placement. But then what should I expect from 3x3? I don't have an easily portable 3x3 MIMO client (I really should upgrade my laptop I guess). But if I multiplied the blue line by 1.5, it would exceed the red line. So we're back either to MIMO being able to exceed the Shannon Limit, or to having to multiply the red line (by 3 now I guess) in which case it's unreasonably huge compared to the real throughput.
What am I missing?
(Hmm. I wonder if a 3x3 MIMO client would not actually get much better results in the sloped section, but would simply un-flatten part of the flat section. If so, that would lend credence to my growing theory that in a room with lots of reflections, ie. imperfect non-orthogonal signals, MIMO has little to do with beating the Shannon Limit and more to do with dealing effectively with your own reflections.)
2014-06-24 »
QotD:
"""
It does look like $VENDOR is using doxygen as a parsing tool. There are python source files that mention reading doxygen XML files to generate proxy code.
"""
2014-06-25 »
I have been working on a theory. It's a corollary to Parkinson's Law, which is "work expands so as to fill the time available for its completion."
My new version is: "Complexity expands to use all the brainpower available." Interestingly, the reason "moonshots" work is that it makes the basic problem you're working on so fundamentally difficult that you don't have as much room to wastefully expand the complexity of your solution.
2014-06-26 »
This conference seems pretty interesting, but sadly I will be out of town at the time. Open source cellular network? Yes please.
http://www.hope.net/schedule.html

2014-06-30 »
"How do you know someone is a Googler? They will tell you how their entire company is the most smartest in the entire multiverse.
If you are so smart why are twiddling around bits in gmail for breadcrumbs when you could have started your own company or gotten into
academia?"
– the Internet
Yeah, why?!
Every day, I ask myself, "Why didn't I get into academia?" and come up empty.
Why would you follow me on twitter? Use RSS.