
2023-04-15 »
Systems design 2: What we hope we know
Someone asked if I could write about the rise of AI and Large Language Models (LLMs) and what I think that means for the future of people, technology, society, and so on. Although that's a fun topic, it left me with two problems: I know approximately nothing about AI, and predicting the future is hard even for people who know what they're talking about.
Let's try something else instead. I'll tell you a bunch of things I do know that are somehow related to the topic, and then you can predict the future yourself.
Magic
I think magic gets a bad reputation for no good reason.
First of all, you might be thinking: magic doesn't actually exist. I assure you that it does. We just need to agree on a definition. For our purposes, let's define magic as: something you know is there, but you can't explain.
Any sufficiently advanced technology is indistinguishable from magic.
— Arthur C. Clarke
One outcome of this definition is that something which is mundane and obvious to one person can be magic to another. Many of us understand this concept unconsciously; outside of storybooks, we more often say something "feels like" magic than we say it "is" magic. Magic is a feeling. Sometimes it's a pleasant feeling, when things go better than they should for reasons we don't understand. Sometimes it's an annoying feeling, when something works differently than expected and you really want to know why.
People often say Tailscale feels like magic. This is not a coincidence. I've never seen anyone say ChatGPT feels like magic. That makes me curious.
Magical thinking
On the other hand, people who believe AIs and specifically LLMs possess "intelligence" are often accused of "magical thinking." Unlike magic itself, magical thinking is always used derisively. Since we now know what magic means, we know what magical thinking means: a tendency to interpret something as magic instead of trying to understand it. A tendency to care about outcomes rather than mechanisms. The underlying assumption, when someone says you're a victim of magical thinking, is that if you understood the mechanisms, you could make better predictions.
When it comes to AI, I doubt it.
The mechanisms used in AI systems are pretty simple. But at a large scale, combined cleverly, they create amazingly complex emergent outcomes far beyond what we put in.
Emergent outcomes defy expectations. Understanding how transistors work doesn't help you at all to explain why Siri sucks. Understanding semi-permeable cell membranes doesn't help much in figuring out what's the deal with frogs. Mechanisms are not the right level of abstraction at all. You can't get there from here.
Magical thinking, it turns out, is absolutely essential to understanding any emergent system. You have to believe in magic to understand anything truly complex.
You see, magical thinking is just another way to say Systems Design.
Emergent complexity
I don't want to go too far into emergent complexity, but I think it's worth a detour since many of us have not thought much about it. Let me link you to three things you might want to read more about.
First and most newsworthy at the moment, there's the recently discovered aperiodic monotile:
Monotile image
by Smith, Myers, Kaplan, and Goodman-Strauss, 2023
The monotile is a surprisingly simple shape that, when tiled compactly across a plane of any size, creates a never-repeating pattern. It was hard to discover but it's easy to use, and creates endlessly variable, endlessly complex output from a very simple input.
Secondly, I really enjoyed The Infinite Staircase by Geoffrey Moore. It's a philosophy book, but it will never be accepted as serious philosophy because it's not written the right way. That said, it draws a map from entropy, to life, to genetics, to memetics, showing how at each step along the ladder, emergent complexity unexpectedly produces a new level that has fundamentally different characteristics from the earlier one. It's a bit of a slog to read but it says things I've never seen anywhere else. Moore even offers a solution to the mind/body duality problem. If you like systems, I think you'll like it.
Thirdly, the book A New Kind of Science by Stephen Wolfram has lots and lots of examples of emergent complexity, starting with simple finite state automatons of the sort you might recognize from Conway's Game of Life (though even simpler). For various reasons, the book got a bad reputation and the author appears to be widely disliked. Part of the book's bad reputation is that it claims to describe "science" but was self-published and not peer reviewed, completely unlike science. True, but it's shortsighted to discount the content because of that.
The book also made a lot of people mad by saying certain important empirical observations in physics and biology can't be reduced to a math formula, but can be reduced to simple iteration rules. The reasons people got mad about that seem to be:
-
an iteration rule is technically a math formula;
-
just using iterations instead of formulas hardly justifies calling for a "New Kind of Science" as if there were something wrong with the old kind of science;
-
scientists absolutely bloody despise emergent complexity → systems design → magical thinking.
Science is the opposite of magical thinking. By definition. Right?
Hypotheses
A friend's favourite book growing up was Zen and the Art of Motorcycle Maintenance. It's an unusual novel that is not especially about motorcycle maintenance, although actually it does contain quite a lot of motorcycle maintenance. It's worth reading, if you haven't, and even more worth reading if you're no longer in high school because I think some of the topics are deeper than they appear at first.
Here's one of my highlights:
Part Three, that part of formal scientific method called experimentation, is sometimes thought of by romantics as all of science itself because that’s the only part with much visual surface. They see lots of test tubes and bizarre equipment and people running around making discoveries. They do not see the experiment as part of a larger intellectual process and so they often confuse experiments with demonstrations, which look the same. A man conducting a gee-whiz science show with fifty thousand dollars’ worth of Frankenstein equipment is not doing anything scientific if he knows beforehand what the results of his efforts are going to be. A motorcycle mechanic, on the other hand, who honks the horn to see if the battery works is informally conducting a true scientific experiment. He is testing a hypothesis by putting the question to nature.
The formation of hypotheses is the most mysterious of all the categories of scientific method. Where they come from, no one knows. A person is sitting somewhere, minding his own business, and suddenly—flash!—he understands something he didn’t understand before. Until it’s tested the hypothesis isn’t truth. For the tests aren’t its source. Its source is somewhere else.
A lesser scientist than Einstein might have said, “But scientific knowledge comes from nature. Nature provides the hypotheses.” But Einstein understood that nature does not. Nature provides only experimental data.
I love this observation: much of science is straightforward, logical, almost rote. It's easy to ask questions; toddlers do it. It's not too hard to hire grad student lab assistants to execute experiments. It's relatively easy for an analyst or statistician to look at a pile of observations from an experiment and draw conclusions.
There's just one really hard step, the middle step: coming up with testable hypotheses. By testable, we mean, we can design an experiment that is actually possible to execute, that will tell us if the hypothesis is true or not, hopefully leading toward answering the original question. Testable hypotheses are, I've heard, where string theory falls flat. We have lots of theories, lots of hypotheses, and billions of dollars to build supercolliders, but we are surprisingly short of things we are able to test for, in order to make the next leap forward.
The book asks, where do hypotheses come from?
Science is supposed to be logical. Almost all the steps are logical. But coming up with testable hypotheses is infuriatingly intuitive. Hypotheses don't arise automatically from a question. Even hypotheses that are obvious are often untestable, or not obviously testable.
Science training doesn't teach us where hypotheses come from. It assumes they're already there. We spend forever talking about how to run experiments in a valid way and to not bias our observations and to make our results repeatable, but we spend almost no time talking about why we test the things we test in the first place. That's because the answer is embarrassing: nobody knows. The best testable hypotheses come to you in the shower or in a dream or when your grad students are drunk at the bar commiserating with their friends about the tedious lab experiments you assigned because they are so straightforward they don't warrant your attention.
Hypotheses are magic. Scientists hate magic.
Engineering
But enough about science. Let's talk about applied science: engineering. Engineering is delightful because it doesn't require hypotheses. We simply take the completed science, the outcome of which has produced facts rather than guesses, and then we use our newfound knowledge to build stuff. The most logical and methodical thing in the world. Awesome.
Right?
Well, hold on.
In the first year of my engineering programme back in university, there was a class called Introduction to Engineering. Now, first of all, that's a bad sign, because it was a semester-long course and they obviously were able to fill it, so perhaps engineering isn't quite as simple as it sounds. Admittedly, much of the course involved drafting (for some reason) and lab safety training (for good reasons), but I've forgotten most of that by now. What I do remember was a simple experiment the professor had all of us do.
He handed out a bunch of paperclips to everyone in the class. Our job was to take each paperclip and bend the outer arm back and forth until it snapped, then record how many bends each one took. After doing that for about five minutes, we each drew a histogram of our own paperclips, then combined the results for the entire class's collection of paperclips into one big histogram.
If you know engineering, you know what we got: a big Gaussian distribution (bell curve). In a sample set that large, a few paperclips snapped within just one or two bends. More lasted for three. A few amazingly resilient high-performers lasted for 20 or more bends ("the long tail"). And so on.
At that point in our educations most of us had seen a Gaussian distribution at least once, in some math class where we'd been taught about standard deviations or whatever, without any real understanding. The paperclip experiment was kind of cool because it made the Gaussian distribution feel a lot more real than it did in math formulas. But still, we wondered what any of this had to do with engineering.
I will forever be haunted by the professor's answer (paraphrased, of course):
Nobody in the world knows how to build a paperclip that will never break. We could build one that bends a thousand times, or a million times, but not one that can bend forever. And nobody builds a paperclip that can bend a thousand times, because it would be more expensive than a regular paperclip and nobody needs it.
Engineering isn't about building a paperclip that will never break, it's about building a paperclip that will bend enough times to get the job done, at a reasonable price, in sufficient quantities, out of attainable materials, on schedule.
Engineering is knowing that no matter how hard you try, some fraction of your paperclips will snap after only one bend, and that's not your fault, that's how reality works, and it's your job to accept that and know exactly what fraction that is and design around it, because if you do engineering wrong, people are going to die. But what's worse, even if you do engineering right, sometimes people might die. As an engineer you are absolutely going to make tradeoffs in which you make things cheaper in exchange for a higher probability that people will die, because the only alternative is not making things at all.
In the real world, the failure rate is never zero, even if you do your job perfectly.
-- My engineering professor
And after that he shared a different anecdote:
I know some of you were top of your class in high school. Maybe you're used to getting 100% on math tests. Well, this is engineering, not math. If you graduate at the top of your engineering class, we should fail you. It means you didn't learn engineering. You wasted your time. Unless you're going to grad school, nobody in the world cares if you got an 80% or a 99%. Do as little work as you can, to learn most of what we're teaching and graduate with a passable grade and get your money's worth. That's engineering.
-- My engineering professor
That is also, it was frequently pointed out at the time, the difference between engineering and computer science.
(I'm proud to say I successfully did not graduate at the top of my engineering class.)
Software engineering
Back in the 1990s when I was learning these things, there was an ongoing vigorous debate about whether software development was or could ever be a form of engineering. Most definitions of engineering were not as edgy as my professor's; engineering definitions mostly revolved around accountability, quality, regulation, ethics. And yes, whose fault it is when people die because of what you made.
I know many people reading this weren't even alive in the 1990s, or not programming professionally, or perhaps they just don't remember because it was a long time ago. But let me tell you, things used to be very different back then! Things like automated tests were nearly nonexistent; they had barely been invented. Computer scientists still thought correctness proofs were the way to go as long as you had a Sufficiently Smart Compiler. The standard way to write commercial software was to throw stuff together, then a "quality assurance" team would try running it, and it wouldn't work, and they'd tell you so and sometimes you'd fix it (often breaking something else) and sometimes there was a deadline so you'd ship it, bugs and all, and all this was normal.
I mean, it's normal now too. But now we have automated tests. Sometimes.
Although much software development today is still not software engineering, some software development today is software engineering. Here are some signs of engineering that you can look for:
- Monitoring and tracking error rates
- SLOs and SLAs and uptime targets
- Distributed system designs that assume and work around the fact that every component will fail
- Long-time-period bug burndown charts
- Continuous improvement and user pain tracking
- Well-tested "unhappy paths" such as degraded operation or inter-region migrations
In short, in software engineering, we acknowledge that failures happen and we measure them, characterize them, and compensate for them. We don't aim for perfection.
Software development that isn't engineering is almost the same: failures still happen, of course. Perfection is still not achieved, of course. But only engineers call that success.
Brute force and cleverness
There are two ways to solve an engineering problem: the "brute force" way and the clever way.
Brute force is the easiest one to describe. You just do something (say graph traversal) in the obvious way, and if that's too slow, you buy more CPUs or bandwidth or whatever and parallelize it harder until the solution comes through within an acceptable amount of time. It costs more, of course, but computers are getting pretty cheap compared to programmer time, so often, the brute force approach is better in all relevant dimensions.
The best thing about brute force solutions is you don't need very fancy engineers to do it. You don't need fancy algorithms. You don't need the latest research. You just do the dumbest thing that can possibly work and you throw a lot of money and electricity at it. It's the ultimate successful engineering tradeoff.
There's only one catch: sometimes brute force simply cannot get you what you want.
We can solve any problem by introducing an extra level of indirection… except for the problem of too many levels of indirection.
— possibly David J. Wheeler
via Butler Lampson,
via Andrew Koenig,
via Peter McCurdy
Here's a simple example: if I want to transfer a terabyte of data in less time, I can increase my network throughput. Throughput is an eminently brute-forceable problem. Just run more fibers and/or put fancier routers on each end. You can, in theory, with enough money, use parallelism to get as much aggregate throughput as you want, without limit. Amazing!
But the overall outcome has limits imposed by latency. Let's say I get myself 100 terabytes/sec of throughput; my single terabyte of data uses only 0.01 seconds, or 10 milliseconds, of capacity. That's pretty fast! And if I want it faster, just get me 1000 terabytes/sec and it'll only use 1 millisecond, and so on.
But that 1 millisecond is not the only thing that matters. If the other end is 100 milliseconds away at the speed of light, then the total transfer time is 101 milliseconds (and 100 milliseconds more to wait for the acknowledgement back!), and brute force will at best save you a fraction of the one millisecond, not any of the 100 milliseconds of latency.
Web developers know about this problem: even on the fastest link, eliminating round trips greatly speeds up page loads. Without this, typical page load times stop improving after about 50 Mbps because they become primarily latency-limited.
Throughput can always be added with brute force. Cutting latency always requires cleverness.
Negative latency
Speaking from a systems design point of view, we say that all real-world systems are "causal": that is, outputs are produced after inputs, never before. As a result, every component you add to a flow can only add latency, never reduce it.

In a boxes-and-arrows network diagram, it's easy to imagine adding more brute force throughput: just add more boxes and arrows, operating in parallel, and add a split/merge step at the beginning and end. Adding boxes is easy. That's brute force.
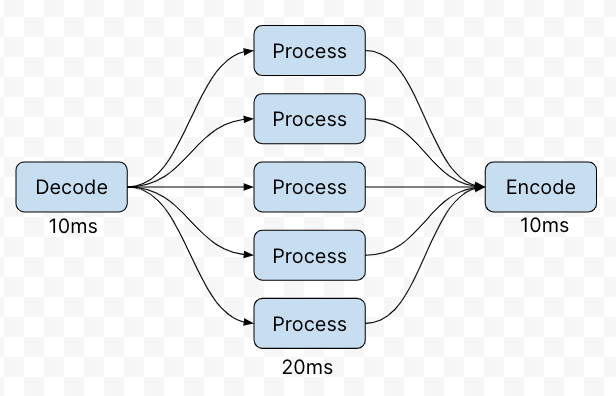
But the only way to make latency go down, causal systems tell us, is to either remove boxes or reduce the latency added by the boxes.
This is often possible, certainly. On a web page, incur fewer round trips. In a router, find ways to speed up the modulation, demodulation, and switching layers. On the Internet, find a more direct route. In a virtual reality headset, eliminate extra frames of buffering or put the compositor closer to the position sensors.

All these things are much harder than just adding more links; all of them require "better" engineering rather than more engineering; all of them have fundamental limits on how much improvement is available at all. It's hard work making causal systems faster.
Now, here's the bad news: systems designers can violate causality.
Scientists Do Not Like This.
Engineers are not so thrilled either.
You merely need to accurately predict the next word future requests, so that when someone later asks you to do work, it's already done.
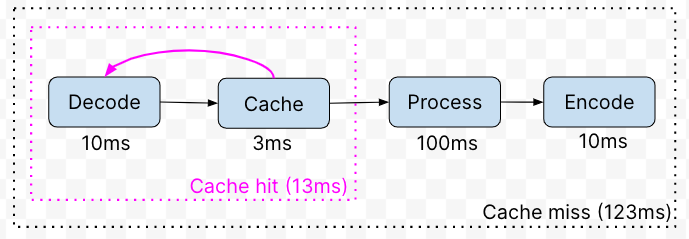
The result is probabilistic. If you guess wrong, the predictor box slightly increases latency (by having to look up the request and then not find it, before forwarding it on). But if you guess right, you can massively reduce latency, down to nearly nothing. And even better, the more money you throw at your predictor, the more predictions you can run pre-emptively (a technique known as "prefetching"). Eventually one of them has to be right. Right?
Well, no, not in any non-trivial cases. (A trivial case would be, say, a web service that increments every time you call it. A Sufficiently Smart Predictor could be right every time and never have to wait for the request. Some people call this Edge Computing.)
(By the way, any cache counts as a predictor, even if it doesn't prefetch. A cache predicts that you will need its answers again later so it keeps some of them around and hopes for the best, still reducing latency on average.)
Anyway, predictors violate causality, depending on your frame of reference for causality. But they can't do it reliably. They only work when they get lucky. And how often they get lucky depends on the quality of—oh no—their hypotheses about what you will need next.
You remember where hypotheses come from, right? Magic.
All caches are magic. Knowing their mechanism is not enough to predict their outcome.
(By the way, this is one of the reasons that Cache Invalidation is one of the "two hard problems in computer science.")
Insight
In my last year of high school, the student sitting next to me asked my English teacher why their essay only got a B while mine got an A+. The teacher said: the difference is... insight. Read Avery's essay. It says things I've never heard before. You want to do that. To get an A+, write something insightful.
My classmate was, naturally, nonplussed. I still remember this as some of the least actionable advice I've ever heard. Be more insightful? Sure, I'll get right on that.
(By an odd coincidence my computer at the time, my first ever Linux PC, was already named insight because I thought it sounded cool. I migrated that hostname from one home-built PC to another for several years afterward, Ship of Theseus style, so that no matter how tired and uncreative I might feel, I would always have at least one insight.)
Anyway, you guessed it. Insight is magic.
Conciseness
You will have noticed by now that this article is long. As I've gotten older, my articles seem to have gotten longer. I'm not entirely sure why that is. I'm guessing it's not especially caused by an Abundance of Insight.
I apologize for such a long letter - I didn't have time to write a short one.
— Blaise PascalMark Twain
To be fair, however, I think there's at least some insight hidden away in here.
But let's say we wanted to distill this post down to something equally useful but shorter and easier to absorb. That leads us to an important question. Is shortening articles brute force, or is it clever?
I think the answer is complicated. Anyone can summarize an article; grade schoolers do it (with varying degrees of success) in their book reports. Very bad computer software has been writing auto-abstracts poorly for years. Cole's Notes charges good money for their service. ChatGPT summarizes stuff quite well for a computer, thank you.
Perfection is achieved, not when there is nothing more to add, but when there is nothing left to take away.
― Antoine de Saint-Exupéry
So summarization, or conciseness, or maybe we call it information compression, can be done with little to no insight at all. Perhaps to do it better requires some insight: which parts are worth highlighting, and which are worth leaving out? How do we take even one sentence and say it with fewer words? Exactly which parts of Macbeth should we include because they are going to be on the test? These are hard jobs that require some kind of skill.
Or maybe we need to draw a distinction between producing insight and recognizing insight. After all, the good parts of this essay are the insightful parts; anything you already knew can be left out. Something you didn't already know, I bet you can recognize with less effort than it took for me to write it.
I don't know much about art, but I know what I like.
— apparently nobody knows who said this
Perhaps summarization is not the ability to produce insight, but rather the ability to recognize what other people will experience as insight.
But Avery, you promised me some opinions about AI
No I didn't.
But let's tie all this together. Let's say you have a Large Language Model AI, trained on all the text in the world. We understand the mechanisms (engineering) but the outcomes are surprising and emergent (magic). Its job is to repeatedly predict the next word that would come if a person wrote it – a form of negative latency, or non-causality. From this, for reasons we don't really understand, it can say an impressive variety of unexpectedly meaningful things.
It's quite good at summarizing. I don't know how good. I wonder if there's a way to quantify that.
Summarizing well requires the ability to recognize and highlight insight. I don't know if it's good at that. I think it might be.
When you have all the text in the world memorized, that means you have access to all the insights that have ever been written. You need only recognize them, and have a good idea of what the reader knows already, and you can produce insights – things the reader has never heard before – on demand. You can get an A+ from my English teacher. Can our AI do that? I don't know. Certainly sometimes, maybe not reliably yet. Any time it does, it will feel like magic. Someone else's insight, delivered at the right moment, is as good as an entirely new insight.
But can LLM AIs produce entirely new insights? I don't know. Good question.
Can I? I don't know that either. This whole article was just a series of quotes and book recommendations.
Where do insights come from, anyway?
They don't teach that in science class.
Epilogue
I asked an AI to improve this article. With apologies to Samuel Beckett, here is ChatGPT's account, expurgated, accelerated, improved and reduced, respectively.
ChatGPT: Clean up this article to give it a coherent thesis and a clear beginning, middle, and end.
The article "Systems Design 2: What We Hope We Know" by Paul Graham is a thought-provoking exploration of the rise of AI and Large Language Models (LLMs) and their impact on the future of people, technology, and society. However, the author admits that predicting the future is difficult, even for experts, and that they know very little about AI. Instead of discussing AI, the author explores the concept of magic, magical thinking, and systems design, and how they are all interconnected.
The author begins by defining magic as something that you know is there, but you cannot explain. They argue that magic gets a bad reputation for no good reason and that many of us understand the concept of magic unconsciously. The author notes that magical thinking is a tendency to interpret something as magic instead of trying to understand it. It is a tendency to care about outcomes rather than mechanisms. The author points out that understanding emergent complexity requires a belief in magic, or what is referred to as magical thinking. They explain that emergent outcomes defy expectations, and understanding how they work requires a deeper level of abstraction that cannot always be explained through mechanisms.
The author offers a few examples of emergent complexity, such as the monotile, which is a surprisingly simple shape that, when tiled across a plane of any size, creates a never-repeating pattern. The author also recommends two books, "The Infinite Staircase" by Geoffrey Moore and "A New Kind of Science" by Stephen Wolfram, that delve into emergent complexity and offer insights into how complex systems work.
The article then explores the formation of hypotheses in scientific method and how it is the most mysterious of all the categories. The author notes that hypotheses are the foundation of scientific inquiry, and yet, science training does not teach us where hypotheses come from or how to form them. They argue that hypotheses are magic, and scientists hate magic. The author points out that the best testable hypotheses come spontaneously, and that hypotheses don't arise automatically from a question.
The article then differentiates between science and engineering and discusses how engineers accept failures and make tradeoffs. They explain that engineering is about building things that work well enough and that engineering is knowing that no matter how hard you try, some fraction of your creations will fail, and that's how reality works. The author highlights the importance of software engineering and discusses how some software development today is software engineering. They point out that engineers who can accept failures and make tradeoffs are the ones who will succeed in the future.
The author then goes into the brute force and clever way to solve engineering problems and how cutting latency always requires cleverness. They explain that brute force is the easiest way to solve engineering problems, but that sometimes it simply cannot get you what you want. The author notes that cutting latency always requires cleverness, and that engineers who can do this are the ones who will succeed in the future.
In conclusion, the author argues that understanding emergent complexity requires a belief in magic or magical thinking. They also highlight the importance of engineering and how it accepts failures and makes tradeoffs. The article concludes by pointing out that cutting latency always requires cleverness, and that engineers who can do this are the ones who will succeed in the future. The article is a fascinating exploration of the interconnectedness of magic, emergent complexity, systems design, and engineering, and how they all play a role in shaping the future of technology and society.
ChatGPT: Tell me the most important insights in this article.
- Magic is something we know is there but can't explain, and it is essential to understanding any emergent system.
- Magical thinking is a tendency to interpret something as magic instead of trying to understand it, and it is often used derisively.
- The mechanisms used in AI systems are pretty simple, but at a large scale, combined cleverly, they create amazingly complex emergent outcomes far beyond what we put in.
- Engineering is knowing that no matter how hard you try, some fraction of your paperclips will snap after only one bend, and that's not your fault, that's how reality works, and it's your job to accept that and know exactly what fraction that is and design around it, because if you do engineering wrong, people are going to die.
- There are two ways to solve an engineering problem: the "brute force" way and the clever way.
- The only way to make latency go down is to either remove boxes or reduce the latency added by the boxes.
ChatGPT: Say something insightful about this topic that is not already in the article, and which the audience is not expected to know already.
One thing worth noting is that the rise of AI and LLMs has brought about both excitement and concerns. On one hand, these technologies have the potential to revolutionize various industries and improve our lives in ways we can't even imagine yet. On the other hand, there are concerns about the ethical implications of AI, such as job displacement and bias in decision-making. It's important for us to continue to monitor and evaluate the development and implementation of these technologies to ensure that they benefit society as a whole, rather than just a select few. Additionally, it's worth noting that while AI and LLMs are impressive and powerful tools, they are not a panacea for all problems. It's important to recognize the limitations and potential pitfalls of these technologies, and to use them in conjunction with human intelligence and expertise to achieve the best outcomes.
ChatGPT: This article is too boring to read. Summarize it in two sentences.
The author discusses the rise of AI and Large Language Models (LLMs) and how they are often accused of "magical thinking". He gives examples of how magical thinking is essential to understanding emergent systems and how engineering is about building products that are good enough to get the job done, not perfect.
Why would you follow me on twitter? Use RSS.