
2015-04-01 »
"I’m kicking off a CTO search for a scaling business in NYC- think ZocDoc meets Uber."
– recruiter email
I'm trying to think of that. But every time I try, my eyes open even wider in terror.
2015-04-02 »
Argh, the price of 24 hour cheese dogs is skyrocketing to $2.50. I'm gonna need another raise.
2015-04-06 »
"Task completion was good with 4 of 5 completing the setup task. All 5 rated it very to extremely easy..."
Hmm.
2015-04-07 »
Most interesting thing I learned at Stuart Cheshire's talk last week: TCP retransmits due to congestion don't waste any bandwidth or cause any reduction in net throughput.
So if you use ECN (a thingy that lets the congested router tag your packets, rather than dropping them, to indicate you should slow down), you don't increase throughput at all.
What?! Crazy, right? But it makes perfect sense when you think about it: the congested link didn't have enough room for your packet, which is why they had to drop it. You have to retransmit another one, but the "retransmit" isn't the second time the packet was sent: it's really the first time. After all, last time around, it was never sent!
Every connection from A to B only has one bottleneck link; all the other ones, by definition, have some leftover space. So the fact that you sent the packets twice over some of those links is irrelevant, because they had room to spare anyhow.
As Stuart said, "throughput is the ultimate perishable resource. Use it now, or it's gone forever." TCP retransmits only use up throughput that otherwise would have been for naught(*).
He then went on to show how iperf absolutely won't show any measurable improvement from ECN for this reason. However, there is more to the world than iperf, and ECN actually does help latency, just not throughput.
(*) When packets are dropped for non-congestion reasons, such as device drivers with stupid bugs (whee!), then retransmits are wasteful and this logic does not apply.
2015-04-08 »
Don't talk to me about "premature" optimization until you've changed your DRAM timings to synchronize better with a graphics loop.
http://trixter.oldskool.org/2015/04/07/8088-mph-we-break-all-your-emulators/
On racing the beam: "...changing the system default DRAM refresh from its default interval of 18 to 19, to get the DRAM refresh periods to line up with CRTC accesses."
On their full-bitrate MOD player for the PC speaker: "Each sample must take exactly 288 cycles to calculate and output or else the sound goes completely pants. This was very difficult to achieve. 4.77 MHz / 288 = 16572 Hz sample output."
I'm also amused by producing 1024-colour mode on the 4-colour CGA adapter.
2015-04-14 »
Another thing I learned from Stuart Cheshire's talk a couple of weeks ago is the usefulness of TCP_NOTSENT_LOWAT. Or more specifically, I learned what it even does and how it differs from just SO_SNDLOWAT or SO_SNDBUF.
Short version: it's better than those things and you should probably use it instead.
Longer version:
Naive use of SO_SNDBUF leads to bufferbloat. The proper value of SO_SNDBUF (at least, if you plan to fill the whole buf) is around 2x the bandwidth-delay product, or else you get either suboptimal speed, or excessive bufferbloat. The problem is, only TCP has a good estimate of the real bandwidth-delay product; that's its job. So if you use SO_SNDBUF, you're overriding what TCP knows, and you'll probably be wrong. (Sadly, not-so-old TCP implementations just used dumb SO_SNDBUF values, so you had to override it.)
SO_SNDLOWAT sounds like it might be helpful, but it never was, so Linux doesn't even implement it, at least according to man socket(7).
TCP_NOTSENT_LOWAT is a mix between the two. It makes it so that select() won't return true for writable when there are TCP_NOTSENT_LOWAT bytes still waiting to be sent, beyond the TCP window. Now, that's a few double negatives, so let's try that again: your socket selects true for writable only if it's worthwhile buffering up more stuff to keep the stream busy. Otherwise, it tells you not to write anything else. However, you actually can still write more stuff if you want and SO_SNDBUF is large enough. (If you use this feature, it's safe to set SO_SNDBUF as large as you want, because you mostly are trying not to fill it all.)
The idea is that if you have traffic of various priorities waiting to be sent out, you want to put low-priority stuff into the socket buffer only if you're sure no high-priority stuff will arrive before it gets sent. You wait until the buffer is emptying out (but not so empty that you're losing throughput) and then insert the highest-priority stuff you have, then go back to waiting.
The nice part is that the kernel does all the important magic, such as figuring out the additional number of bytes required for the delay-bandwidth product (which varies over time and is added to the NOTSENT_LOWAT value). All you have to do is write data when you're asked to do so, and you magically get less TCP buffer bloat.
2015-04-17 »
20 years already? Somehow djb's work keeps echoing through all the stuff I end up doing.
https://www.eff.org/deeplinks/2015/04/remembering-case-established-code-speech/
2015-04-20 »
I keep flipping to the Promotions tab in gmail, but alas, not the promotion I was looking for.
2015-04-21 »
I'm going to rename the "experiment framework" to the "bikeshedding framework," to better reflect how it is used.
2015-04-23 »
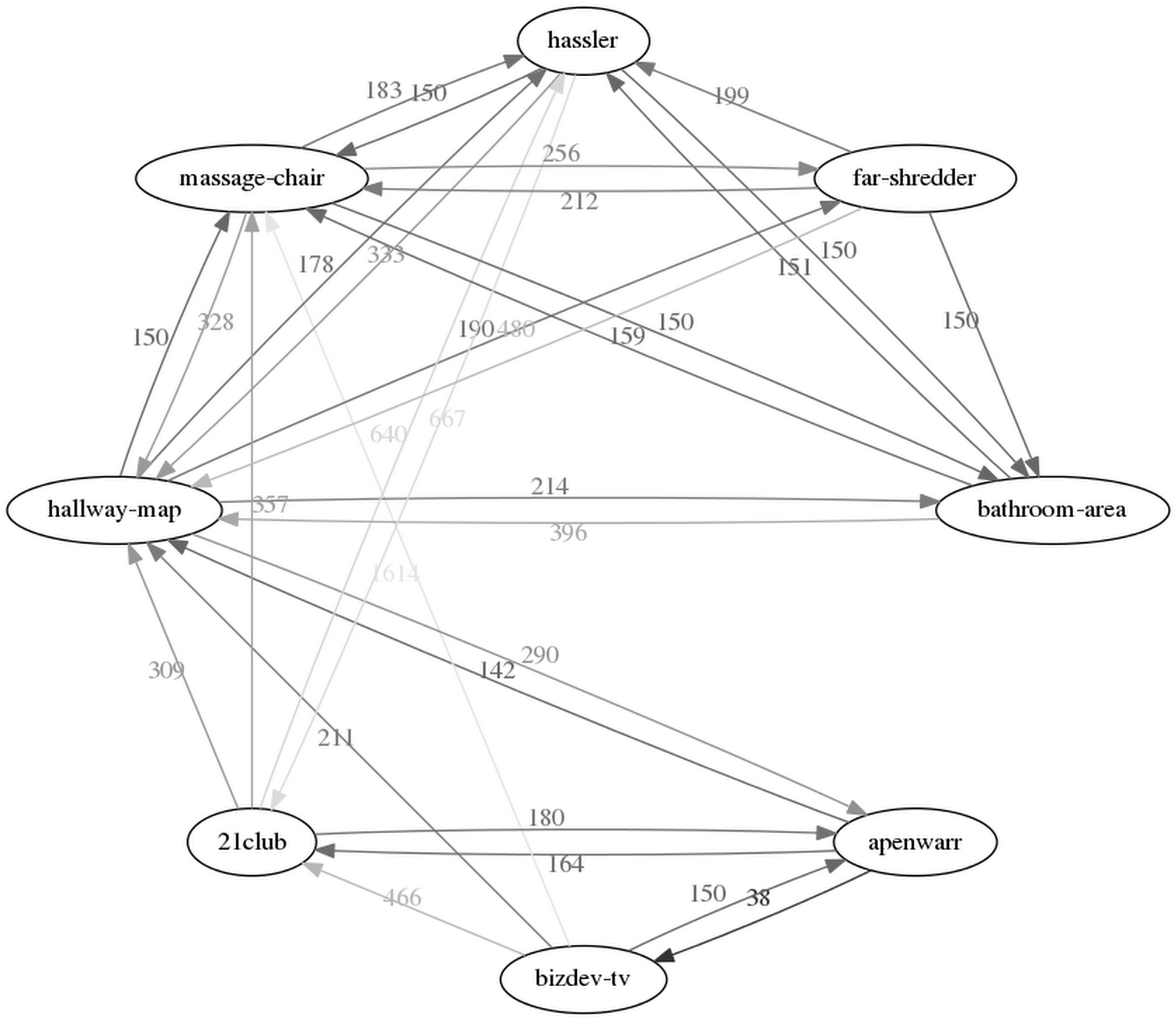
Mesh power!
What we mainly learn from this diagram is a) my path to the bathroom is a long, circuitous one, and b) the 'circo' program from graphviz is pretty fun, and c) the hallway is some kind of communication nexus.
On a system that started off with ~80 Mbps of TCP throughput (which is about right for a 2x2 radio at 20 MHz... too bad it's a 3x3 radio though), using the mesh I was able to still sustain 14 Mbps from a distance of about 114 AnandSteps. That's about a 6x decline, or about 3 hops at 50% signal power.
By my rough calculation, that means a 4x4 radio @ 80 MHz should be able to do 14 Mbps * 2 * 4 = 112 Mbps at that distance, which comes out to about 5 TVs (and absolutely no bandwidth leftover for a safety margin or actually using wifi for Internet traffic).
On the other hand, 114 AnandSteps in linear distance is, hmm, maybe 250 feet, which would be a 62,500 sq.ft. one-story house. Which is maybe unreasonably large. (It would also need more than 8 mesh nodes to properly cover the whole area, but in theory could still connect any two points in about 3 hops.)
With only two hops (more reasonable for a reasonably-sized home), speeds were around 35 Mbps, so the 4x4 @ 80 equivalent would be about 280 Mbps, which seems to leave plenty of room for TVs and Internet.
Disclaimer: these estimates are extremely rough.

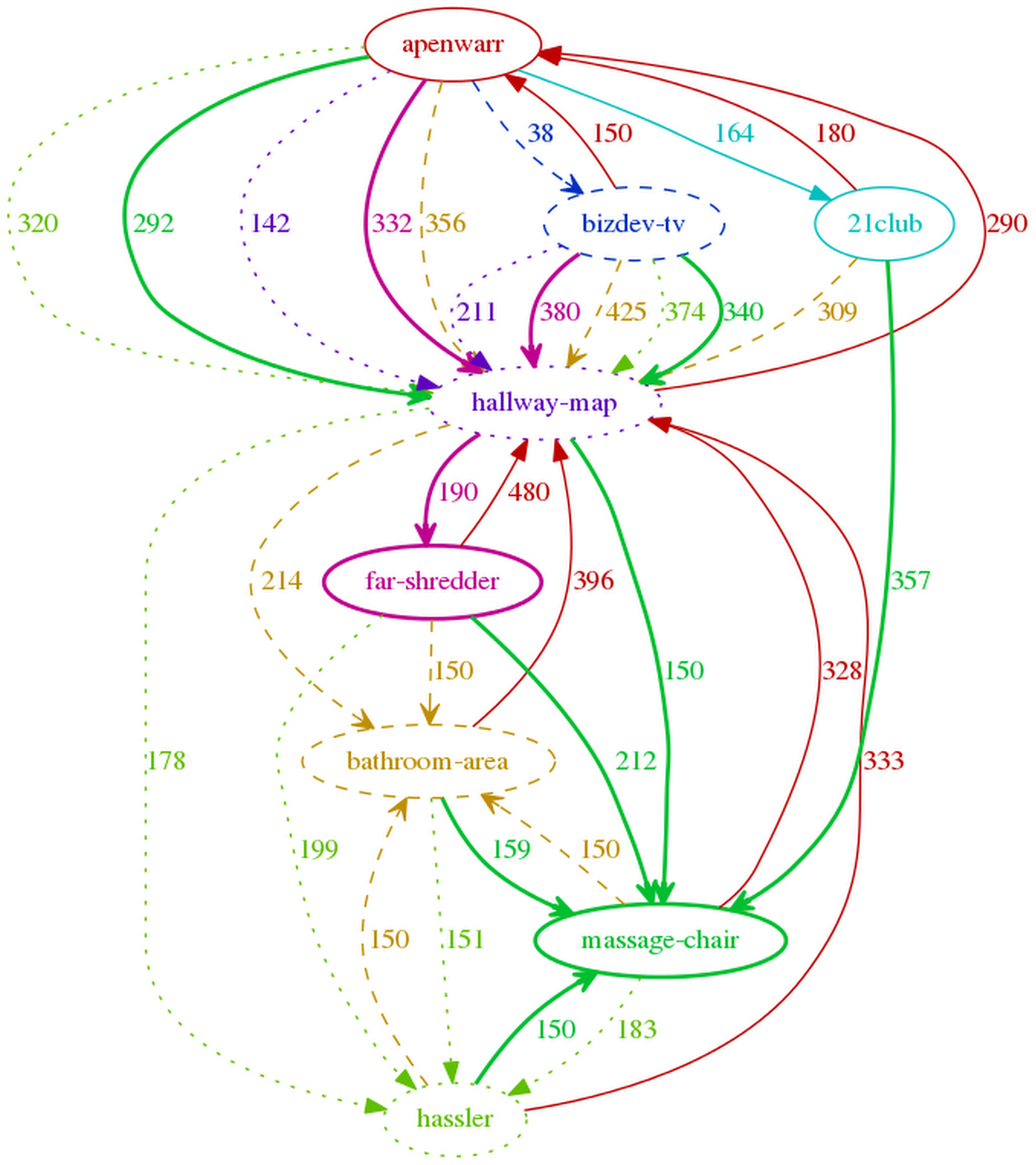
2015-04-28 »
More mesh power! This diagram is much more confusing than the previous one, but also more correct. Each colour/stipple corresponds to the particular destination node of that colour. Each arrow indicates that if you're on a given node, you would traverse the arrow of that colour to (eventually) reach the target node of that colour. For example, follow the solid green arrows to eventually reach the solid green circle.
Interestingly, what we can finally see here is that the system has optimized every path down to at most two hops. That's better than I expected for such a large coverage area. But I can't say it's wrong.
Why would you follow me on twitter? Use RSS.