
2016-12-05 »
I assume this is what all gpg users are like.
https://petertodd.org/2016/cypherpunk-desert-bus-zcash-trusted-setup-ceremony

2016-12-06 »
"Sprint's network reliability is within 1% of Verizon," says the Sprint ad. Well, wow. I bet I could keep my network up for 99 out of 100 minutes too.
2016-12-07 »
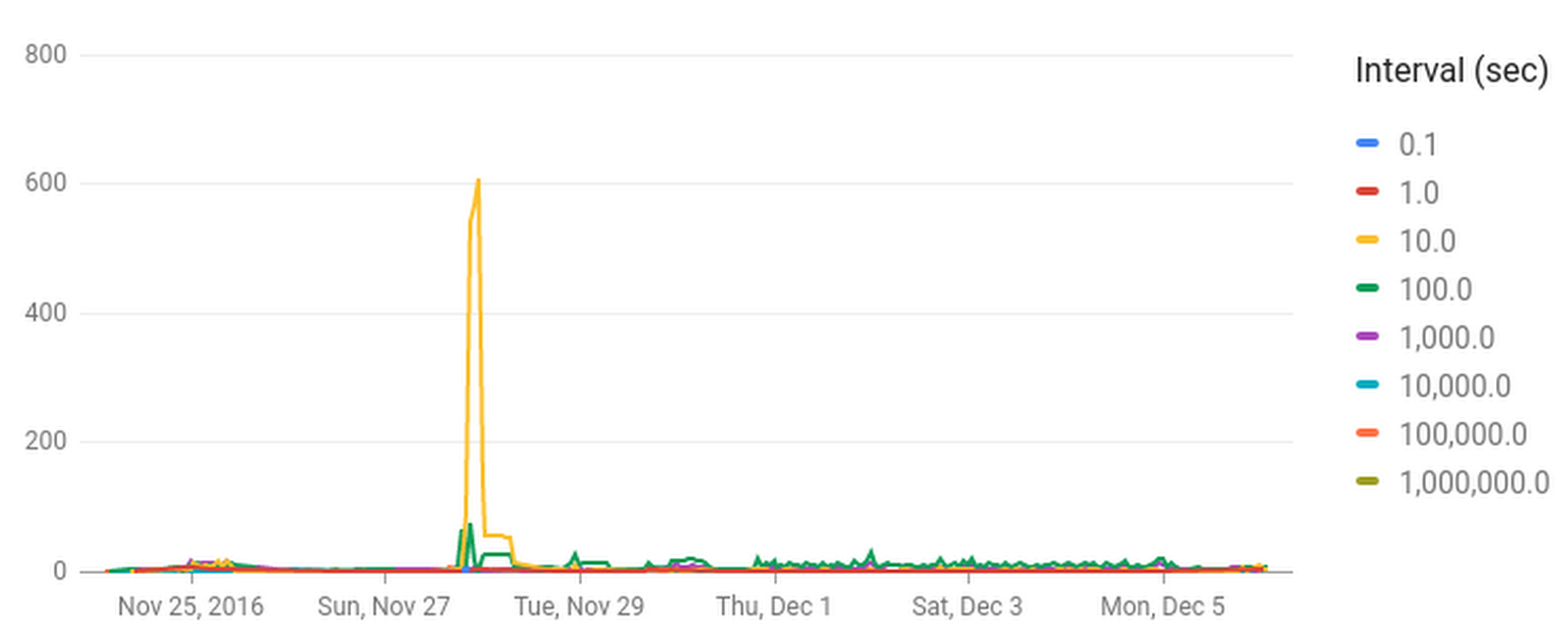
I have here a dashboard I've titled "dhcp fishiness analytics." As you can see, for this customer, the fishiness spikes to over 600 at one point.
2016-12-11 »
"""I noticed that a lot of dogfood feedback in the form of "I
didn't find a bug, I just don't like the way it worked" were closed as
Working as Intended. It's like people don't want dogfood feedback to tell
them that their super-PM vision is wrong, they want dogfooders in order to
avoid having to write integration tests. WAI is like saying, "shut up and
find a real bug", rather than "let's work together on making the best
product".
"""
2016-12-13 »
The four motivators
A long time ago someone sent me an article, maybe it was from Harvard Business Review, that talked about the four things that might motivate any given worker in their job. That article has really stuck with me since then. The idea is that, of course, we are all motivated by all four things, but most people have a "primary" motivator that matters more than the rest. I think that article helps explain why maybe 75% of your coworkers always seem crazy, no matter which side of the fence you're on.
It's now fuzzy from years of retelling the story in my own words, but as I remember it, the four motivators are:
1. Loyalty to a person
2. Loyalty to a vision
3. Money (and perks, etc)
4. Loyalty to a social group or environment
1. Loyalty to a person
Humans, some much more than others, have a tendency to follow a strong, charismatic leader. The world is a complicated place, and we don't always know the best path. Many engineers just want to concentrate on engineering, and let someone else tell us which direction to engineer in, with the stipulation that we want some reason to believe that it's the right direction. A strong leader can provide that confidence. Sometimes we call this a "cult of personality," because religious cults are formed around the same desire - the desire to believe in something, through believing in someone. Steve Jobs is the most obvious example, but you can also imagine Larry Ellison and Bill Gates had their ultra-loyal followers in their heyday.
You might also look up to a manager, director, exec, or just an individual contributor you think is a good role model. We have plenty of those.
2. Loyalty to a vision
In contrast to #1, this one is about something more abstract. Organizing the world's information. Bringing more, faster, abundant Internet to more people. Robots with laser eyes. Whatever. If you're strongly motivated by #2, you will put up with nearly anything as long as it doesn't get in the way of your goal. They can take away your free snacks, give you a Mountain View-grade commute, and pack your desks in like sardines, as long as you still feel like you're making a difference in the world. Once you stop making a difference, all the snacks in the world won't keep you around.
(Having no free snacks or food, or having too-cramped working quarters, reduces productivity, because now you have to stop and go find sustenance in the middle of the day or you can't concentrate. Even people motivated purely by a vision care about efficiency in achieving that vision.)
This one is of course the classic Silicon Valley story, but many people are not motivated as strongly by #2 as they want to believe. Few people can afford to only be motivated by #2, because it's actually quite hard to tell if you're making a difference or not. The other motivators can be used as proxies since they are easier to measure. (eg. I may not like Larry much, but I'm pretty sure if I follow him I'll make a difference, so okay. Or I have no idea if we're doing a good thing, but Microsoft sure pays me a lot of money, so I must be doing something worthwhile, so I can sleep at night.)
3. Money (and perks, etc)
The pure form of this is called a "mercenary." Everyone seems to look at mercenary motivation as shallow and negative, but let's not judge it too harshly. Almost all of us are motivated by money to some degree. Some of the best engineers I know are happy to sell their services to the highest bidder, as long as their career doesn't stagnate (since that would lower the price in the next round).
Every dollar you get paid, every bonus, every gift and stock option or share you get offered, all of that is a motivation to come work for an employer or to stay there. If your health plan gets cut or your options go underwater or, heaven forbid, your Christmas bonus gets reduced, that matters. If you have the choice between two companies with strong leaders and a vision you agree with, but one of them has a better chef, maybe you pick that one.
Another perk that people sometimes forget is social standing. If you work at a big, well-known company that people love, then you get instant respect just for saying you work there. That matters to some people more than others. I know people whose parents didn't understand what they did (and thought maybe they should have been a doctor or lawyer instead) until they said they worked at IBM or Google, and then finally their families accepted their career choice. Working at a place that gets featured in magazines for being one of the world's best workplaces isn't so bad either. And getting paid a lot, well, we all know money buys prestige.
Interestingly, people aren't too sensitive to the absolute value of their income, but they're really sensitive to relative values. They're always on the lookout for trendlines, because emotionally, that's all you can feel. It's kinda like how in a car you can feel acceleration, but you can't really feel velocity.
4. Loyalty to a social group or environment
Your social group is the people you work with. If this motivates you, then you don't want to let down your co-workers. Even if the project seems dumb and your leader is a jerk and the pay is rotten, if your teammates are all working hard, you'll show up and do your best to help them succeed, and you'll feel good about it afterwards.
On the other hand, you'll be sad if they lose perks. You'll be extra sad if one of the above motivators drops and your friends decide they don't want to work here anymore, which is different from caring about the perks directly, even though the net effect looks the same. You'll be sad if your leader makes a dumb decision and decides to communicate poorly, because now you can't trust them anymore, and you liked trusting them, because trust is the basis of a healthy team. You'll be sad if the product plan gets fuzzy and your friends get demotivated, because your friends were happier when they were motivated. You'll care when the culture starts to change, because you won't like the new people as much as the people who left. And a little more confusingly, you'll be sad if you even perceive that one of these things might be happening, even if the predicted outcome (your friends being hurt) hasn't visibly happened yet.
When you see someone with an opinion or a feeling about something that happens, see if you can slot it into one of the four categories. Maybe then you can understand them better, even if you don't feel the same way.
2016-12-14 »
Almost every programming problem I knew of back in the 1990s is now solved. The main exception, "distributed computing is really complicated and nobody has any idea how to make it work reliably," is now everybody's day job. Although defining "reliably" turned out to be harder than we thought.
Relatedly, percentiles were not too useful to me back in the 1990s, and seemed kinda contrived. Nowadays they're surprisingly essential.
2016-12-20 »
Today I was reminded that dumb IoT light UIs have a decades-old predecessor. (Okay, two predecessors: there's also the clapper.)
"""
An example of failure of this principle is the buttons on the arm of the seat in an aeroplane. The man that put the buttons in place obviously never rode in an aeroplane. How may the passenger turn his light on or off? The passenger may by good luck and dogged perseverance, trying this button ton and that, discover the secret. Why should it be a puzzle to turn a light on or off?
"""
– W. Edwards Deming

2016-12-22 »
"Meanwhile, we have 'steampunk' fantasies of worlds where stuff works again because hipstercoders haven't gotten their oblivious hands on it yet."
– carton
2016-12-26 »
Highlights on "quality," and Deming's work as it applies to software development
Back when I was in university, I visited a bookstore and found, in the physics section, a group of books on relativity. One of the shortest books with the least glossy cover had a surprising author: Albert Einstein. Surprising? Well, he formed the theory, but everyone knows he wrote science papers, not books, and for advanced physicists, not average people, right?
Apparently not. You can still buy Relativity, the Special and General Theory on Amazon, including a Kindle format for $0.99. From Einstein's own description, "The present book is intended, as far as possible, to give an exact insight into the theory of Relativity to those readers who, from a general scientific and philosophical point of view, are interested in the theory, but who are not conversant with the mathematical apparatus of theoretical physics."
Sure enough, the book is very readable, and didn't require any advanced math in order to understand the concepts. Einstein himself understood his theory so well that he was able to explain it in terms an average person can understand.
In contrast, the other relativity books on the same shelf were more complicated and harder to read. Maybe the authors understood just as well as Einstein, and had the benefit of decades more research in the area, but somehow they managed to obscure the main point. Perhaps part of genius, or some kinds of genius, is just the ability to explain your deep thoughts to others.
Anyway, I took that as an important lesson: don't be afraid to go back to the original source when you want to learn something. It's not always as intimidating as it sounds.
Which brings us to this Christmas holiday, where I had a few hours here and there to catch up on reading, and I set out to learn about the quality revolution in manufacturing (generally agreed to have started in Japan, albeit with ironic American influence). I wanted to know: What was the big insight? Did westerners finally catch on? Does it all just seem obvious to us now? And even more importantly, does it apply to software development, or is software too different from manufacturing for the concepts to really apply? (In particular, it seems clear that manufacturing quality is largely about doing a one-time design and reliably producing zillions of identical items, and the problems seem to be mainly in the reliable reproduction. In software, reproduction is the easy part.)
In my stint as a "Semiconductor Industry Veteran" (The Guardian's words, not mine :)) for four months in the late 1990s, I had heard buzzwords related to this topic. Notably: Toyota Production System (TPS), Six Sigma, Zero Defects, and Total Quality Management. I didn't know much about them, just the names. Well, I had heard that in the TPS, any worker could push a big red button and stop the assembly line if they found a defect, but I didn't really see how that could help. Six Sigma sounded fishy... six sigma from what? Just three sigma is better than 99%, so Six Sigma must be essentially Zero Defects, which sounds nice, it must be what Japanese companies were doing. Total Quality Management sounds like a scam just from the name, so let's just ignore that one.
So it's a vacation, but I have limited time, what should I read? After a
bit of investigation, one thing the 1990's Japanese System fan
fiction management consultants all seemed to have in common was an
influence by W.
Edwards Deming, an American who apparently either co-invented or at
least evangelized all this stuff around Japan (I'm still not quite sure).
Maybe let's go there and see if we can find the original source.
(It later turned out that Deming was in turn heavily influenced by Walter A. Shewhart's work in the 1920s, but that's going back a bit far, and it seems like Deming generalized his work to a bunch of new areas, so let's stick with Deming for now.)
A quick trip to Amazon brought me to Deming's last book, The New Economics for Industry, Government, Education, which wins the dubious award for "most overpriced e-book by a dead guy I have ever seen." But on the other hand, if it's that expensive, maybe there's something good in there, so I bought it.
It was even better than I thought. I've never highlighted so many passages in a single book before. I don't even like highlighting passages in books. And this is a pretty short book. It gets right to the point, demolishing everything I thought I knew. (It also includes some well-placed jabs at Six Sigma, a management technique supposedly based on Deming's methods!)
(Around the part of the book where he was insulting Six Sigma, I thought I'd better look it up to see what it's about. It's indeed pretty awful. Just to start with, the "six" sigma are just because they count the entire range from -3 standard deviations to +3 standard deviations. That's an error margin +/- 3 stddev, or ~99.7%. It's not "six" standard deviations by any normal human's terminology. It gets worse from there. Safe to ignore.)
Anyway, back to demolishing everything I thought I knew. I was looking for advice on how to improve quality, which means I was kinda surprised when early in the book I found this:
I listened all day, an unforgettable Thursday, to 10 presentations, reports of 10 teams, on reduction of defects. The audience was composed of 150 people, all working on reduction of defects, listening intently, with touching devotion to their jobs. They did not understand, I think, that their efforts could in time be eminently successful-no defects-while their company declines. Something more must take place, for jobs.
In a book that I thought was about reducing defects, this was a little disconcerting.
We move on to,
Have you ever heard of a plant that closed? And why did it close? Shoddy workmanship? No.
Um, what is this? Maybe I should go get a Total Quality Management book after all. (Just kidding. I refuse to acknowledge any religion with a name that dumb.)
He moved on to blast a few more things that many of us take as axiomatic:
The effect of Hard work? Best efforts? Answer: We thus only dig deeper the pit that we are in. Hard work and best efforts will not by themselves dig us out of the pit. [...]
Ranking is a farce. Apparent performance is actually attributable mostly to the system that the individual works in, not to the individual himself. [...]
In Japan, the pecking order is the opposite. A company in Japan that runs into economic hardship takes these steps:2 1. Cut the dividend. Maybe cut it out. 2. Reduce salaries and bonuses of top management. 3. Further reduction for top management. 4. Last of all, the rank and file are asked to help out. People that do not need to work may take a furlough. People that can take early retirement may do so, now. 5. Finally, if necessary, a cut in pay for those that stay, but no one loses a job. [...]
Appointment of someone as Vice President in Charge of Quality will he disappointment and frustration. Accountability for quality belongs to top management. It can not he delegated. [...]
It is wrong to suppose that if you can't measure it, you can't manage it-a costly myth. [...]
If you can accomplish a [numerical quality/goal] goal without a [new] method, then why were you not doing it last year? There is only one possible answer: you were goofing off. [...]
The bulletin America 2000: An Educational Study, published by the Secretary of Education, Washington, 18 April 1991, provides a horrible example of numerical goals, tests, rewards, but no method. By what method? [...]
It is important that an aim never be defined in terms of a specific activity or method. [...]
This diagram [process flow diagram], as an organization chart, is far more meaningful than the usual pyramid. The pyramid only shows responsibilities for reporting, who reports to whom. It shows the chain of command and accountability. A pyramid does not describe the system of production. It does not tell anybody how his work fits into the work of other people in the company. If a pyramid conveys any message at all, it is that anybody should first and foremost try to satisfy his boss (get a good rating). The customer is not in the pyramid. [...]
Suppose that you tell me that my job is to wash this table. You show to me soap, water, and a brush. I still have no idea what the job is. I must know what the table will be used for after I wash it. Why wash it? Will the table be used to set food on? If so, it is clean enough now. If it is to be used for an operating table, I must wash the table several times with scalding water, top, bottom, and legs; also the floor below it and around it. [...]
The U.S. Postal Service is not a monopoly. The authorities of the postal service are hampered by Congress. If the U.S. Postal Service were a monopoly, there would be a chance of better service. [...]
The interpretation of results of a test or experiment is something else. It is prediction that a specific change in a process or procedure will be a wise choice, or that no change would be better. Either way the choice is prediction. This is known as an analytic problem, or a problem of inference, prediction. Tests of significance, t-test, chi-square, are useless as inference-i.e., useless for aid in prediction. Test of hypothesis has been for half a century a bristling obstruction to understanding statistical inference. [...]
Management is prediction. [...] Theory is a window into the world. Theory leads to prediction. Without prediction, experience and examples teach nothing. To copy an example of success, without understanding it with the aid of theory, may lead to disaster.
I could keep quoting the quotes. They are all about equally terrifying. Let me ruin any suspense you have might left: you aren't going to fix quality problems by doing the same thing you were doing, only better.
This book also quickly answered my other questions: yes, it is applicable to software development. No, westerners have still not figured it out. No, software will not get better if we just keep doing what we were doing. Yes, Japanese manufacturers knew this already in the 1980s and 1990s.
Statistical Control
This post is getting a bit long already, so let's skip over more ranting and get to the point. First of all, I hope you read Deming's book(s). This one was very good, quite short, and easy to read, like Einstein's Relativity was easy to read. And you know it works, because his ideas were copied over and over, poorly, eventually into unrecognizability, ineffectiveness, and confusion, the way only the best ideas are.
Just for a taste, here's what I think are the two super important lessons. They may seem obvious in retrospect, but since I never really see anybody talking about them, I think they're not obvious at all.
The first lesson is: It's more important for output to have a continuous (usually Gaussian) distribution than to be within specifications. Western companies spend a lot of time manufacturing devices to be "within spec." If an output is out of spec, we have to throw it away and make another one, or at least fix it. If it's in spec, that's great, ship it! But... stop doing that. Forget about the spec, in fact. Real-life continuous processes do not have discontinuous yes/no breakpoints, and trying to create those requires you to destabilize and complexify your processes (often by adding an inspection or QA phase, which, surprisingly, turns out to be a very bad idea). I don't have time to explain it here, but Deming has some very, very strong opinions on the suckiness of post-manufacturing quality inspection.
The second lesson is: Know the difference between "special causes of variation" and "common causes of variation." Special causes produce outputs outside the continuous statistical distribution you were expecting. In my line of work, the continous variable might be Internet throughput, which varies over time, but is pretty predictable. A special cause would be, say, an outage, where you get 0 Mbps for a while before the outage is fixed. (On the other hand, if you're running an ISP, the pattern of your outages may actually be its own statistical distribution, and then you break it down further. Drunk drivers knocking down poles happens at a fairly predictable rate; accidentally deleting your authentication key on all the routers, causing a self-induced accidental outage is a special event.)
The reason it's so important to differentiate between special and common causes is that the way you respond to them is completely different. Special causes are usually caused by, and thus can be fixed or avoided by, low-level individual workers, in the case of manufacturing or repetitive work. In software (although Deming doesn't talk about software), special causes are weird bugs that only trigger in certain edge cases but cause major failure when they do. Special causes can often be eliminated by just fixing up your processes.
Common causes are simple variation inside your normal statistical distribution. It's tempting to try to fix these, especially when you're unlucky enough to get an outlier. Wifi throughput got really low for a few seconds, lower than two standard deviations fro the mean, isn't that weird? We got a surprisingly large number of customer service calls this week, much more than last week, what did we do wrong? And so on.
The great insight of Deming's methods is that you can (mostly) identify the difference between common and special causes mathematically, and that you should not attempt to fix common causes directly - it's a waste of time, because all real-life processes have random variation. (In fact, he provides a bunch of examples of how trying to fix common causes can make them much worse.)
Instead, what you want to do is identify your mean and standard deviation, plot the distribution, and try to clean it up. Rather than poking around at the weird edges of the distribution, can we adjust the mean left or right to get more output closer to what we want? Can we reduce the overall standard deviation - not any one outlier - by changing something fundamental about the process?
As part of that, you might find out that your process is actually not in control at all, and most of your problems are "special" causes. This means you're overdriving your process. For example, software developers working super long hours to meet a deadline might produce bursts of high producitivity followed by indeterminate periods of collapse (or they quit and the whole thing shuts down, or whatever). Running them at a reasonable rate might give worse short-term results, but more predictable results over time, and predictable results are where quality comes from.
My job nowadays is trying to make wifi better. This separation - which, like I said, sounds kind of obvious in retrospect - is a huge help to me. In wifi, the difference between "bugs that make the wifi stop working" and "variable performance in wifi transfer speeds or latency" is a big deal. The former is special causes, and the latter is common causes. You have to solve them differently. You probably should have two different groups of people thinking about solving them. Even further, just doing a single wifi speed test, or looking at the average or a particular percentile to see if it's "good enough" is not right. You want to measure the mean and stddev, and see which customers' wifi is weird (special causes) and which is normal (common causes).
Anyway, it's been a good vacation so far.
2016-12-28 »
Why complex corporate approval chains are stupid, in the words of W. Edwards Deming, in 1992:
"""
The reader will perceive at once the source of the problem-two signatures [on the factory employee time card]. The worker signs the card, leaving the foreman to correct the mistakes. The foreman signs it under the supposition that the worker should know better than anyone what he did. Result: omissions, inconsistencies, and wrong entries. Solution: Cross out the foreman's space on the 900 cards that you will use next week; same for the 900 cards for the following week. By then, you can have new cards with no space for the foreman. Further, if a worker could have filled out the card correctly-be sure that he could-return the card to him. You don't need to stamp a message on it to say that his pay may be delayed. He will understand this without help. The problem will vanish in three weeks.
"""
– W. Edwards Deming
In related news, this is one reason that manual testing departments are a bad idea. It encourages you to not check your work carefully yourself.
2016-12-29 »
I've been doing some light reading on quality control in manufacturing. Lots of applicable stuff in there.
"The consultant was going about it the wrong way. Using the manufacturer's claim as the lower control limit (action limit) is confusing special causes with common causes, making matters worse, guaranteeing trouble forever. A wiser procedure would be to get statistical control of the machine, under the circumstances in place. Its performance might turn out to be 90 per cent of the maximum speed as specified by the manufacturer, or 100 per cent, or 110 per cent. The next step would be continual improvement of the machine and use thereof."
– W. Edwards Deming
More musings:
http://apenwarr.ca/log/?m=201612#26
2016-12-30 »
Visual Basic is back! And about time, too. It's like if appengine had a front end, basically.
2016-12-31 »
Guess I might as well get in on the Leap Second Smear posts. Here's the ntp adjustment levels (in microseconds) across GFiber devices over the last couple of days.
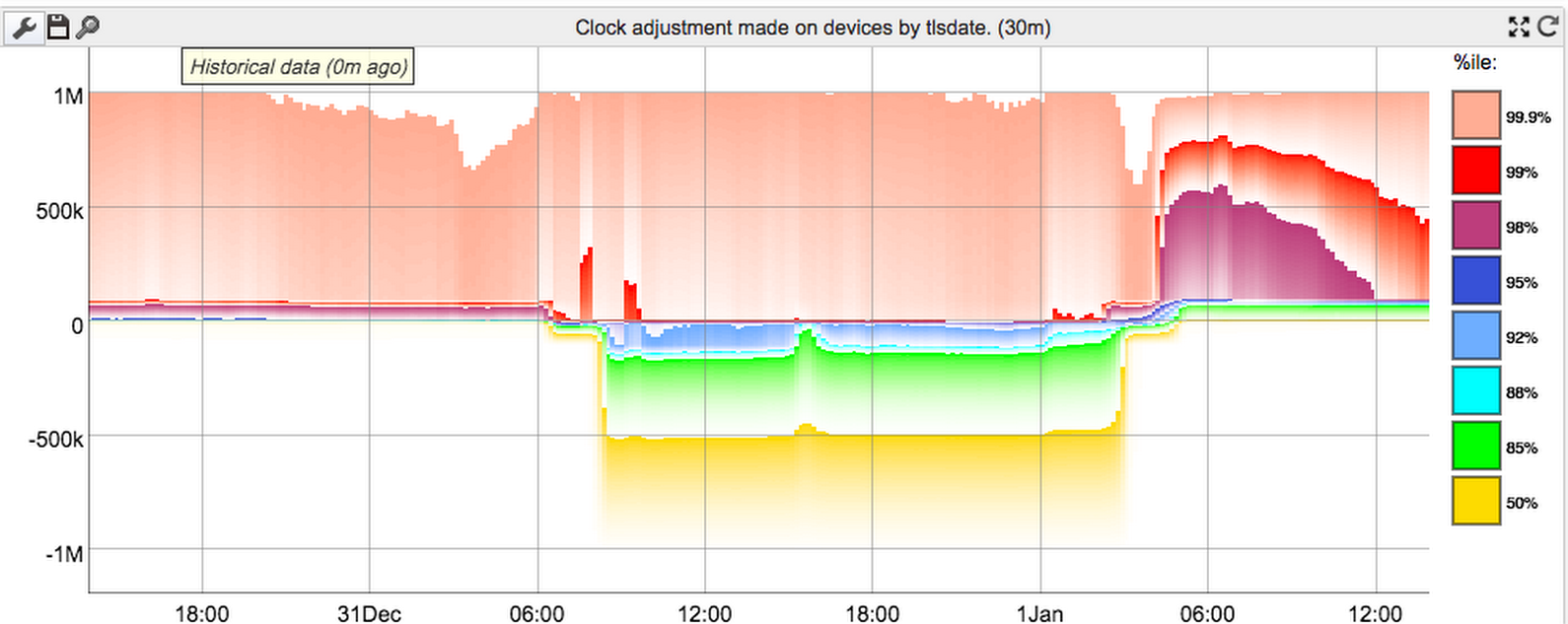
It probably deserves a little explanation. Under normal circumstances (ie the left side of the graph), devices have generally low (single-digit milliseconds) absolute error, except during initial boot, when they run tlsdate to get a rough sync. Unfortunately tls rounds down to the next-lowest integer second, so the first ntp sync after boot will typically (ignoring network latency) have between +0 and +1000ms of adjustment on top of the tls date. Since there's always a low-level number of devices rebooting for whatever reason, the upper percentiles are (almost) always around 1000ms. We really should filter out those early syncs, since they're completely misleading about the overall precision of our clock sync during real use. (Even the lower percentiles are probably dominated by these giant boot time errors.)
At some point, the Google ntp servers started smearing in the leap second. We use djb clockspeed, which spends a lot of effort trying to get the right clock rate and does a good job at it, so our actual refresh rate for hitting the ntp servers is quite low (it can be several hours between polls). Unfortunately, leap second smearing is precisely designed to screw up the clock speed, which is the worst case scenario for djb clockspeed, especially with infrequent polling. That means different devices can end up quite heavily diverged (in the +ve direction) from the server's time, if they don't check the ntp server for quite a while after the smear starts. Thus, the correction factor goes negative for a while (middle section). We still don't sync very often (idea: maybe start syncing more frequently when the measured error is higher?), so we then eventually get into overshoot, which is the rightmost section of the graph.
After that it seems to settle down quite rapidly - maybe too rapidly. I can't really explain why it works so well. I expected a bit of "ringing" around zero for a while. But maybe any given device rings a bit, but it averages out rapidly, so the percentile graph loses that granularity.
Why would you follow me on twitter? Use RSS.