
2011-02-03 »
Template for apenwarr's political opinions
It's that time of year again apparently. Rather than fill in the template for you this time, I'll just give you the general outline of what I always think of your pointless and uninformed politically-motivated petition. That way you can guess, in the future, what I will say, and I won't have to actually say it.
First of all, cut it out with the ad-hominem attacks. Stick to the actual issues. If you don't like the other guy's TV ads, and you loudly say so, then you are the one not talking about the issues, and it's your fault. Be better than that. When you rise above the sludge, people will notice. You won't have to tell them.
Pay attention to people's biases. If there's a web site lobbying for something, figure out who runs it. If you agree with a web site lobbying for something, be especially suspicious, because while you agree with their main point, they might be using your general agreeableness to slip by some absolute lies. They're lobbyists! Lobbyists lie! If you don't see any lies on that lobbyist site, YOU ARE A VICTIM OF MANIPULATION.
Remember that most branches of the government are not directly controlled by elected officials. Elected figureheads are at the top of the pyramid, but they swap out frequently and rarely have time to learn every detail. Thus, when an unelected regulator makes a decision, it's rarely motivated by re-election or party sponsors or whatever, because the person making the decision usually doesn't care about those things. The decision might still be wrong for many reasons, but it almost always isn't political reasons. Thus, never trust someone who simplistically tells you otherwise. Find out the real reasons a decision was made.
Try to imagine that the person making a law or regulation is actually a good person who is trying to do the right thing for everyone. Why would a good person have decided to do what you're angry about? Remember, it's a hypothetical honest person, doing what they honestly think is right. Why do they think that? Could someone reach such a high level of office and be that dumb? Imagine you were that dumb; what would you do to achieve that level of power? Or are you perhaps missing something? Can you figure out what you've missed?
Try to remember that Canada is not the United States. We have a vastly, vastly lower degree of corruption, for many reasons. To skip the idealism, one theory is simply that, at 1/10th the size, it's just not worth infiltrating us. Maybe the person making the decision really is a good person.
Note that at least one of the big political parties has policies that aim to make the rich richer. The funny thing is, virtually everyone reading this article is rich, by the literal definition average people use, or they will be rich before they retire. You might not agree with this party's policies, but if you're surprised when a lot of those policies end up directly benefitting you, then you are much less objective than you think you are. You hate them, but you've forgotten why. If you're honest with yourself, you'll find that you're in the uncomfortable position of disagreeing with policies that are really, really good for you personally. That can be a form of high virtue. Does it feel like hating them is virtuous, or reflexive? There's a big difference.
Most of all:
Do your own research. We have the Internet. We can just look stuff up. Government policies and decisions are published in the open, with tonnes of public review. Yet almost nobody ever actually goes to the primary sources before forming an opinion; they trust what their friends tell them. Ask your friends: did you actually read the primary sources? If they say no, they just heard it from their friends, STOP THEM BEFORE THEY HURT SOMEONE.
The only cure for mob mentality is thinking for yourself.
2011-02-04 »
Sshuttle VPN 0.51: now with DNS forwarding and a MacOS GUI
I just released version 0.51 of my Sshuttle VPN. Normally I don't re-announce my projects here unless something really interesting happens, but if you have a Mac, then I think this counts as really interesting:
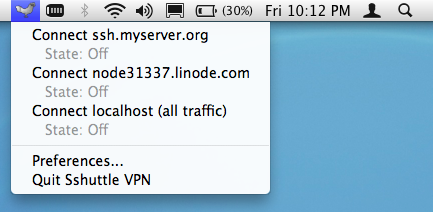
Sshuttle now has a fancy MacOS GUI!
There's not too much to it. Other than the menubar icon, there's just a preferences window:
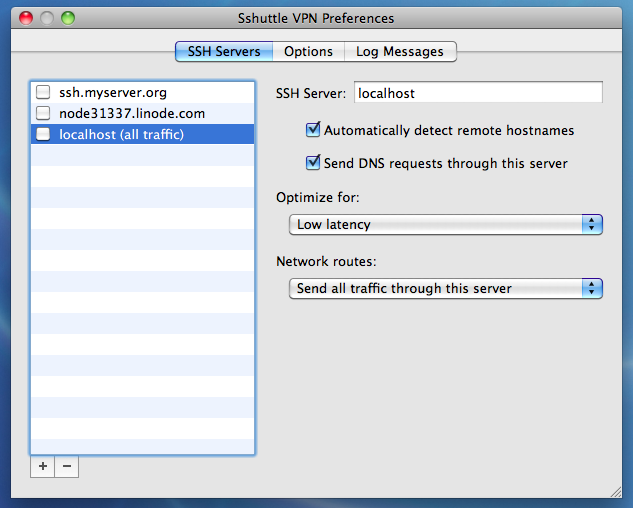
For those just joining us, what's so interesting about sshuttle?
- It's easier to install than any other VPN software in the history of the universe.
- It forwards over a plain ssh session, which means your server doesn't need sshuttle installed and you don't need server admin access.
- Authentication is just ssh authentication; there's nothing new to learn.
- It avoids the tcp over tcp problem that's infamous among simple-minded VPNs.
- You don't have to change any SOCKS settings.
- It's more reliable than ssh's port forwarding, which freezes randomly (at least for me).
- It has latency controls to avoid interactive slowness caused by bufferbloat in ssh.
- You can choose to forward only a subset of your traffic (ie. the subnets that exist on the remote end).
- If you have multiple offices or clients, you can connect to more than one remote network at once.
- You can choose to forward all your TCP traffic to protect yourself from things like FireSheep.
- Since Sshuttle 0.50, you can also capture all DNS requests and send them over the tunnel.
- Since Sshuttle 0.51, we now have a workaround for stupid MacOS 10.6 network-dropping-dead kernel bugs. (Man, Apple should hire me as a QA tester. I'll just write open source software and reveal serious kernel bugs. Of course, they don't ever fix them, so...)
To download the source code (for Linux, MacOS, and FreeBSD), visit the sshuttle page on github.
If you want to just download the precompiled MacOS GUI app, I made a github tag for that: download Sshuttle VPN.app here. (The resulting filename is really stupid, because github's auto-generated download filenames are really stupid. It seems obvious to me that a tag named 'sshuttle-0.51-macos-bin' should result in a file called 'sshuttle-0.51-macos-bin.tar.gz', but no, the generated filename is full of crap. If this upsets you, complain to the github people. I already did. They told me I was wrong.)
Will this be going into the fancy newfangled Mac App Store?
No. Sshuttle needs root access (on your client machine, not on the server), which disqualifies it. Oh well. You'll have to go through the rather trivial process of downloading and extracting the zip file instead.
2011-02-09 »
Daring Fireball linked to me
Oh wow, not only am I internet famous, but now Daring Fireball used my uninformed speculation to inform their uninformed speculation! This, after my original uninformed speculation was inspired by theirs!
I am actually part of an internet circle jerk. Wow. This is too awesome. I love you guys. <snif>
Update 2011/02/09: And The Guardian linked to me too, apparently.
2011-02-10 »
A job posting for the 21st century
Zak at Upverter recent wrote a post titled Interns: How to hire Porn Stars that had a few links to my old articles on hiring interns (which we Waterloovians1 call "co-op students"). I had totally forgotten about Try not to need to advertise for employees, which I recommend as background for the following.
Since my series of articles is about four years old now, the Upverter post reminded me that maybe I should make an update with some of my observations since then. Here's what I've learned.
Silly job titles have become cliches.
I may have been the person who started the recent trend of ridiculous job titles, starting with NITI's old Human Cannonball and Evil Death Ray co-op jobs. In its prime, NITI became infamous among Waterloo co-op students, and those co-op students (ie. spies) have since spread everywhere. I heard fairly reliable rumours that Research in Motion was seriously considering their own silly job descriptions at one point, using ours as a direct model. And I heard that Akoha's original "Python Charmer" video job ad was inspired by one of our co-op students who worked there. As far as I can tell, the "Ruby Ninja Pirate" knockoff job descriptions all find their roots in Akoha's video job ad initiative.
Here's the bad news: Akoha partly missed the point, and everybody after that really missed the point. The point of these job ads was to do something unique that would get people's attention and be really memorable, while accurately representing our work environment. They don't work once they stop being unique, and they don't work if they don't accurately represent your work environment.
We now live in a world where stupid boring companies think they can fool people by using Ninja Python Rock Pornographer job descriptions. It doesn't work; in fact, as far as I'm concerned, stupid job descriptions now have a negative correlation with the kind of company I'd want to work for. If you don't understand why you're being silly, then you don't understand your own fundamental human motivations, so your company has a pretty high probability of failure. That's not sexy.
The silliness was never the point.
I covered this in my earlier Job Titles and Roles article, but it bears repeating: the reason we didn't use standard job titles was that standard job titles come with preconceptions. Preconceptions mean instant inflexibility. Meaningless job titles mean that nobody really knows what their job is, and that's a good thing, because startups live or die by the flexibility of their people.
But silliness and standardization are orthogonal. (Just look at IPsec.) The more famous nonstandard job titles, like "Just a Programmer" or "Member of Technical Staff," also achieve these goals without the distracting silliness.
More rumours from my spies: after a while, Akoha supposedly switched away from silly video job descriptions, because they discovered that the silliness was selecting more for silly people than for good programmers. The Human Cannonball / Evil Death Ray job descriptions were subtly balanced in a way that silly video ads aren't. (I admit that this "subtle balance" was more accidental than purposeful.) For example, you have to be literate to understand the Human Cannonball ad. You even have to use your imagination a bit to understand what a human cannonball has to do with writing software at a startup. (Hint: think of a bull in a china shop.) But you don't even need a working brain to hear, "Porn rocker hermit laser monkey!!" and say "Ooga booga! Me want!"
The people who want to pad their resumes are right.
Zak's article links to another article that suggests people are somehow wrong to want to work at Google to make their resume look more impressive when applying for a "real" job after graduation. Instead, the advice is to get a job at a startup, because you'll get better experience there.
No!
Let me badly paraphrase some ancient wisdom, to wit: Respect your enemies, or they will beat the pants off you.
As a company trying to attract students, you are competing with Google. All the rules of business competition apply, including this one: if you badmouth your competitors, it just makes you look like a sore loser, with emphasis on the "loser."
Google is, from all reports I've ever heard (and oh boy, do a lot of my spies^H^H^H^H^H former co-op students work at Google), a really excellent place to work. Furthermore, it's widely acknowledged that investors are, on average, happier to give money to a company founded by "former Googlers" than by other random people. And you know what? If I was hiring someone, even a student, for my company, all else being equal, I'd absolutely prefer someone who's worked at Google or Apple versus someone who hasn't. Facebook, Twitter, Amazon? The same, maybe not as strongly.
Why does Google make great resume padding? Simple: because they're a great pre-filter. They have a really complicated job interview process and acknowledged high standards. That you managed to sneak by their filters doesn't automatically mean you're great, but it sure means you're great enough that you should get by my (by comparison, stone aged) initial resume filter and probably phone screen. We might as well fly you in right away; we already know Google did and then they were happy enough to give you a job.
Maybe your noname startup has great screening/hiring practices too; we sure did. But a random interviewer at a random company won't know that. They will know about Google.
So anyway, if you're a startup and you want to attract students, that's what you're dealing with. Every student absolutely, positively should try to pad their resume with a job like that. Even if they sat at Google and twiddled their thumbs and stared at the screen in shock and fear and tried not to get noticed for four months, that doesn't matter; they can just lie on their resume and in your interview. It won't work every time, but it's sure better than not having the option.
Will you try to tell students that working for a startup is more valuable than that? If so, instant fail. You'll be lying. They'll know it.
Working for a startup is still valuable experience.
Okay, so working at Google is great for the resume, and as a bonus, if you put some work into it, you'll probably also learn something. (I don't know, I've never worked there, but spies confirm this too.)
But don't get me wrong: if you really want to learn stuff, there is nothing like working at a startup. Every student who wants to get wide experience - as every student should - ought to work for a startup, at least for a while. This is not either/or. You should work for Google or a big name company. You should work for a startup. If you don't do both, you're doing it wrong.
Furthermore, Google recruiters are smart. If you have experience working at a startup, they know what that means. So let's say Google rejected you this time around. If you work at a startup, all that new experience should increase your chances of getting the Google offer next time.
So with all that in mind, here's how I might write a co-op job ad for the 21st century:
RENAISSANCE PERSON >>
I know what you're thinking. You're thinking, "Hmm, maybe I'd better at least apply for a few other jobs in case Google doesn't want me. I don't know how to cook. I really need that free gourmet cafeteria food if I want to survive... but maybe, worst case, with another job, I could work something out. Pay someone to make food for me, somehow. Can you even do that? Or maybe mooch off a co-worker."
THIS IS THE JOB FOR YOU.
If you're smart, you'll make sure to have at least one brand-name company on your resume by the time you graduate. But that's not all you should have: you should have real-life experience working in every aspect of product development and release, from building office furniture and installing your operating system to coding features, fixing bugs, answering support calls, and substituting for the CEO while he's away on his biweekly bender.
This job isn't easy. You'll need every skill you have, plus more. But that's okay, because one of our full-time developers will be your personal mentor and help you develop those skills.
We work reasonable hours, except when we don't want to, and then we work unreasonable hours. Our co-op students release more code in an afternoon than Google co-ops release in a whole work term, and sure, their code works and ours doesn't, but we have PRIDE, dammit, PRIDE, and we'll fix the bugs tomorrow before anybody notices.
We can't hire as many people as the big companies, which means you're going to have to be the best of the best if you want to work here. But that also means we'll give you more responsibility than you'll get anywhere else, which means you'll learn more than you would learn anywhere else. This company was founded by Waterloo co-op students, so we know co-op students can be trusted with responsibility. We also know exactly what we wished we knew when we were your age, duckies, and we'll tell you so you can ignore us and go learn it the hard way.
Here are some skills you should have:
- (list of skills)
And here are some projects we'll be working on:
- (list of projects)
If you do your job right, next time around, you'll have so much experience that you'll get that Google job for sure.
If we do our job right, you won't want it.
Bonus Interview Tip from People Who've Done This Before
When you wear a suit to your interviews, the only jobs it helps you get are the ones where they care how you dress more than how you code.
...
1 For those who don't know, the University of the Waterloo is the university in Canada with the "best reputation." (Yeah, I know, it's not as good as being objectively best, but we take what we can get.) It also has, by a very very very large margin, the best co-op/internship programme of any Canadian university I'm aware of. Students in the co-op programme, which is most of them, have six different four-month work terms before they graduate, at up to six different companies. NITI hired students almost exclusively from U.Waterloo simply because it was consistently easy and the students were consistently high quality, and if you want word-of-mouth to spread among students, it helps if they're all in the same classes.
2011-02-22 »
Chip-and-pin is not broken
I've seen this article about the supposed security holes with chip-and-pin credit cards making the rounds lately. As with my previous article on smartcard PINs, I have just enough knowledge to be dangerous. Which in this case means just enough knowledge to tell you why this latest attack on chip cards is not a very exciting one.
In short, the attackers in the above article have revealed a simple way for anyone to use a stolen chip credit card, without knowing the PIN, regardless of whether or not the credit card reader is online at the time. This security hole is real. I'm not disputing that.
However, it's also not as bad as people are making it sound. Most importantly, chip cards are not even close to as insecure as the old ("magstripe") cards they were designed to replace. And while those old cards had annoyingly high levels of fraud, you as a consumer really didn't need to care, because big faceless megacorporations paid for it. In this case, it's still more secure than before, so you should care even less than before.
Here are three reasons why the current security hole is not very exciting:
1. You have to physically steal the card.
Most fraud on magstripe cards was from copying: anyone with a bit of technical skill can trivially copy a magstripe card just by buying a magstripe writer device for less than $200. Since magstripes are used all over for much more than just financial stuff, there's no regulation about who can buy such devices.
So a common form of attack on magstripes is social engineering. It works like this: go into a store where they swipe your card on a machine. The machine then says "card read error" or "denied" or whatever, and you give up and use a different card or cash. Or maybe they try again on a different terminal, and it mysteriously succeeds this time. But in the meantime, the first terminal has recorded the data on your magstripe - probably less than 1k of data per card. The criminal can pick up the data later, and use it to clone any card that has ever been read by the illegal reader.
Ah, but what about your signature on the back of the card? And how about the hologram of your face that's on some cards? How do they copy that, huh? Easy, they don't: they just rewrite the magstripe on a card with their picture and signature on it. When they take it to a store, the card is physically theirs, but the account number is yours, so they're spending your money, not theirs. Ouch.
Better still, they can simply re-rewrite the magstripe on their card back to their original identity later, leaving little evidence.
So anyway, be suspicious of any vendor who tries to scan your card but then it "fails," especially if they look like they were expecting it. If their reader was that unreliable, they would have stopped using it by now. Report them to your bank. It might help them find some fraudsters.
But anyway, that form of fraud is soon to disappear: your credit card still has a magstripe, but it's only for backwards compatibility with old magstripe-only readers. Chip cards are completely immune to this sort of attack, because the chip interface doesn't tell you the card number: it only gives the reader a one-time transaction authorization code, which you can't use to construct a new card.
Of course, someone who clones your card's magstripe can still copy and use it in a magstripe reader, so you're still susceptible to fraud. But it gets less valuable every day, and vendors who sell expensive stuff - the ideal fraud targets - are the first to upgrade their readers to support chip cards. Someday the magstripe "feature" will be safely turned off entirely.
(It is still possible to read the real account number and secret key information from a chip card and therefore clone it. But it requires extremely messy and unreliable equipment. As far as I know, there are no simple, reliable machines that can do this in a store setting without arousing suspicion. Moreover, any such machine would obviously have only-nefarious purposes, so you'll never be able to buy one for $200 like you can with general purpose magstripe devices.)
By the way, the extra "security code" on the back of your card is a partial protection against the card-copying attack: the security code isn't on the magstripe. So someone who copies your card can't use it for web purchases that need the security code, unless they manually write down the security code while stealing your card, and that would be too obvious. (Unless you're at a restaurant, and the server takes your card into a back room for "processing." But you wouldn't ever let them do that, right?)
2. You have to hack the vendor's card reading terminal.
Another handy thing about the old magstripe card attacks is they work at any store, on any credit card terminal. (Nowadays they only work at terminals that don't support chip cards, because the bank refuses magstripe transactions from chip-capable terminals on chip-capable cards. Getting better!)
That means the standard form of attack would be to steal your card number at a shady corner store or restaurant, then delay for an arbitrary amount of time - you don't want it to be too obvious which shady store stole the number, since they probably stole a bunch all at the same time. Then, take it to an expensive store like Future Shop and buy stuff... untraceably. It has your name on it, not the fraudster, and the vendor is Future Shop, not the fraudster. The perfect crime.
With the chip card hack we're discussing, your crime isn't so perfect anymore. Above, I said that you need to steal the card instead of copying it. That's hard enough to do, but it's doubly hard for another reason: the owner will probably notice and immediately call their bank to cancel it. That means you can't wait a few weeks or months before using the stolen card - you have to do it fast, before the owner notices. So even if you come up with a clever way of stealing cards in large quantities, it'll be a lot easier for the police to track down the theft just by using statistics.
But even worse, to execute the chip-card-without-PIN hack, you have to break the card reader device and make it lie to both the card and the bank. That's not so hard to do, if you're an excellent programmer. Much harder than just copying a magstripe, which any halfway competent techie could do with off-the-shelf equipment. But yes, as with any DRM, it's crackable, so somebody can do it. Based on the "Chip and PIN is Broken" paper, someone already has.
What's much harder, though, is getting a store to use your hacked card reader on their merchant account. You can't just walk into Future Shop and hand them a card and a special card reader and say, "Yeah, charge it to this." No, you'll have to infiltrate a Future Shop and get them to use your special card reader. Not only is that much more traceable - suddenly there are people at Future Shop who know who the criminal is - but it's also not much easier than just stealing the stupid TV in the first place. I mean, if you can sneak into Future Shop, then you can sneak out of Future Shop, right?
Or you could get your own merchant account, I guess, and charge the money through that. But no... not likely. What could be more traceable than opening a merchant account at a bank and then running fraudulent transactions through it? I'm sure there's some way to use a fake identity or something, but again, that's way harder than walking into a chain store, buying something, and walking out again.
3. The only reason it even works is for backwards compatibility.
The third reason this attack is rather boring is that it exploits an optional feature of the EMV specification. Essentially, they independently convince the card, and the bank, that they really don't need a PIN today. In a simpler world, that would be impossible; the card would demand a PIN, and the bank would demand a PIN-authenticated transaction. But because of backwards compatibility and maybe some too-flexible specifications, it's possible to convince the card that the bank has authenticated the PIN, and convince the bank that the card has authenticated the PIN, all at the same time.
Yes, it's a real security hole caused by specification bugs; that attack simply shouldn't be possible to do. And yes, because of that attack, a physically stolen card can be used on a hacked card reader without knowing the PIN, so banks should worry about fraud.
But from my reading of the EMV specification (the spec is available for free online, by the way; google it), the particular modes that make this attack possible are optional. You can just turn them off. Banks just don't want to, because in some situations, those modes let you do a transaction (ie. spend money, thus earning the bank money) where you otherwise couldn't.
If I understand correctly - and maybe I don't, as I didn't read the exact form of the attack too carefully - the main point of confusion is that PINs can be verified either online (by the bank) or offline (by the card), and which one we use is determined by a negotiation between the card, the reader, and the bank. (Interestingly, exactly this was the focus of my previous article on chip cards.) If the reader lies to the card and says the bank isn't available right now (offline mode), and lies to the bank and says the card has requested offline PIN verification (maybe the card is set to require offline verification; that's one of the options in the spec), then the transaction can go through.
Moreover, the bank will store a "PIN Verified" flag that supposedly means the transaction is known to be much safer than an unverified (eg. magstripe) transaction. That might tell a bank's auto-fraud-detection algorithms to relax more than they should, which is probably the real story here. (If you're a bank, you should care about this security hole. If you're a normal person, probably not.)
Bonus trivia: incentives
By the way, here's a bit of information I ran into that I found interesting:
In the magstripe days, most fraud was by default considered the responsibility of the vendor. That is, if a store accepted a fraudulent card and you later reversed the transaction, it was the store who lost the money, not the bank. This seems really cruel to store owners, but the idea was that if you don't give them an incentive to reject faked cards, then they won't be careful. For example, a store has no reason to check your signature or your photo id if it's not them who'll lose in case of fraud. In fact, they have an incentive to not check those things, since checking them slows them down, costs money, and discourages you from shopping there. (Plus, a store can make their own decisions about how careful they want to be. Do we want a fast checkout line in exchange for higher fraud, or a slow checkout line with less fraud? What saves us the most money in the long run?)
Remember, even without professional magstripe fraud, there was still the even more trivial low-tech kind: a teenager steals a credit card from their parents' wallet, walks into a store, and buys something. Signature/photo checks are really hopelessly weak, but at least they reduce that.
Now, putting all the blame on the vendor was supposedly the default, but I suspect it wasn't what actually happened. I'm guessing that, officially or unofficially, if it was proven that a real forged card was used - as opposed to the vendor just not checking the signature carefully enough - that the bank would take on some of the loss. Maybe half, maybe all of it, who knows.
As magstripe fraud got more and more out of control, the industry started switching to chip cards. The problem is, you can't switch the entire world from magstripe to chip all in one day. It's a chicken-and-egg problem. So how do you make it worthwhile for banks to start issuing chip cards - since magstripe fraud isn't their problem - and for stores to upgrade to chip readers?
Someone somewhere (in government, perhaps?) came up with a neat solution: we'll change the liability rules. Nowadays it works like this: if a vendor has a chip-capable reader, card fraud is the bank's fault, so they pay for it. If a vendor only has an old magstripe reader, the vendor pays for it. And this is true whether or not the particular credit card is chip capable, because if it's not, then it's the bank's fault for not issuing a newer card.
I find this to be an extremely clever social hack. It aligns everybody's best interests toward reducing fraud, but requires no fines, laws, agreed-upon industry-wide schedules, deprecation periods, or enforcement.
Summary
The "Chip and PIN is Broken" attack:
- only works if your card is physically stolen;
- only works if the criminal uses a traceable vendor with a modified terminal;
- can be disabled someday by turning off some optional protocol features;
- is a liability issue for banks and/or vendors, but not consumers like you.
My advice:
- If your card is stolen, report it immediately.
- If a vendor has trouble reading your card and doesn't look surprised, consider reporting it to your bank.
- Yes, you still need to monitor your bank statement for incorrect transactions (not just for fraud; incompetence remains rampant too).
- If anyone asks you whether chip cards are more secure than the alternatives, say YES YES OH GOD YES, PLEASE PLEASE LET THE OLD SYSTEM DIE NOW.
I hope that clears things up.
2011-02-28 »
Insufficiently known POSIX shell features
I've seen several articles in the past with titles like "Top 10 things you didn't know about bash programming." These articles are disappointing on two levels: first of all, the tricks are almost always things I already knew. And secondly, if you want to write portable programs, you can't depend on bash features (not every platform has bash!). POSIX-like shells, however, are much more widespread.1
Since writing redo, I've had a chance to start writing a few more shell scripts that aim for maximum portability, and from there, I've learned some really cool tricks that I haven't seen documented elsewhere. Here are a few.
Update 2011/02/28: Just to emphasize, all the tricks below work in every POSIX shell I know of. None of them are bashisms.
1. Removing prefixes and suffixes
This is a super common requirement. For example, given a .c filename, you want to turn it into a .o. This is easy in sh:
SRC=/path/to/foo.c
OBJ=${SRC%.c}.o
You might also try OBJ=$(basename $SRC .c).o, but this has an annoying side effect: it also removes the /path/to part. Sometimes you want to do that, but sometimes you don't. It's also more typing.
(Update 2011/02/28: Note that the above $() syntax, as an alternative to nesting, is also valid POSIX and works in every halfway modern shell. I use it all the time. Backquotes get really ugly as soon as you need to nest them.)
Speaking of removing those paths, you can use this feature to strip prefixes too:
SRC=/path/to/foo.c
BASE=${SRC##*/}
DIR=${SRC%"$BASE"}
Update 2011/03/23: Added quotes around $BASE in the third line at someone's suggestion. Otherwise it's subject to the same wildcard string expansion as in the second line, which is probably not what you want when $BASE contains weird characters. (Note: this is not filename wildcard expansion, it's just string expansion.)
These are cheap (ie. non-forking!) alternatives to the basename and dirname commands. The nice thing about not forking is they run much faster, especially on Windows where fork/exec is ridiculously expensive and should be avoided at all costs.
(Note that these are not quite the same as dirname and basename. For example, "dirname foo" will return ".", but the above would set DIR to the empty string instead of ".". You might want to write a dirname function that's a little more careful.)
Some notes about the #/% syntax:
- The thing you're stripping is a shell glob, not a regex. So "", not "."
- bash has a handy regex version of this, but we're not talking about bashisms here :)
- The part you want to remove can include shell variables (using $).
- Unfortunately the part you're removing from has to be just a variable name, so you might have to strip things in a few steps. In particular, removing prefixes and suffixes from one string is a two step process.
- There's also ##/%%, which mean "the longest matching prefix/suffix" and #/% mean "the shortest matching prefix/suffix." So to remove the first directory only, you could use SUB=${SRC#*/}.
2. Default values for variables
There are several different substitution modes for variables that don't contain values. They come in two flavours: assignment and substitution, as well as two rules: empty string vs. unassigned variable. It's easiest to show with an example:
unset a b c d
e= f= g= h=
# output: 1 2 3 4 6 8
echo ${a-1} ${b:-2} ${c=3} ${d:=4} ${e-5} ${f:-6} ${g=7} ${h:=8}
# output: 3 4 8
echo $a $b $c $d $e $f $g $h
The "-" flavours are a one-shot substitution; they don't change the variable itself. The "=" flavours reassign the variable if the substitution takes effect. (You can see the difference by what shows in the second echo statement compared to the first.)
The ":" rules affect both unassigned ("null") variables and empty ("") variables; the non-":" rules affect only unassigned variables, but not empty ones. As far as I can tell, this is virtually the only time the shell cares about the difference between the two.
Personally, I think it's almost always wrong to treat empty strings differently from unset ones, so I recommend using the ":" rules almost all the time.
I also think it makes sense to express your defaults once at the top instead of every single time - since in the latter case if you change your default, you'll have to change your code in 25 places - so I recommend using := instead of :- almost all the time.
If you're going to do that, I also recommend this little syntax trick for assigning your defaults exactly once at the top:
: ${CC:=gcc} ${CXX:=g++}
: ${CFLAGS:=-O -Wall -g}
: ${FILES:="
f1
f2
f3
"}
Update 2011/03/23: Someone points out that some versions of ash/dash and FreeBSD sh require quotes around the argument when it involves newlines, as in the third line above. POSIX says it should work without the quotes, but that's no use to you if common shells can't do it. So you should use the quotes in this case.
The trick here is the ":" command, a shell builtin that never does anything and throws away all its parameters. I find the above trick to be a little more readable and certainly less repetitive than:
[ -z "$CC" ] || CC=gcc
[ -z "$CXX" ] || CXX=g++
[ -z "$CFLAGS" ] || CFLAGS="-O -Wall -g"
[ -z "$FILES" ] || FILES="
f1
f2
f3
"
3. You can assign one variable to another without quoting
It turns out that these two statements are identical:
a=$b
a="$b"
...even if $b contains characters like spaces, wildcards, or quotes. For
whatever reason, the substitutions in a variable assignment aren't subject
to further expansion, which turns out to be exactly what you want. If $b
was chicken ls you wouldn't really want the meaning of a=$b to be
a=chicken; ls. So luckily, it isn't.
If you've been quoting all your variable-to-variable assignments, you can
take out the quotes now. By the way, more complex assignments like a=$b$c
are also safe.
Update 2011/03/23: A few people have brought up assignments of $* and
$@ as special cases here. From what I can tell, this works in all modern
shells:
x=$*
However, assigning $@ to a variable is unspecified and it doesn't do
anything consistent. But that's okay, because it's meaningless as a
variable assignment (since $@ is not a normal variable); use $* if
you want to assign it.
4. Local vs. global variables
In early sh, all variables were global. That is, if you set a variable inside a shell function, it would be visible inside the calling function after you return. For backward compatibility, this behaviour persists by default today. And from what I've heard, POSIX actually doesn't specify any other behaviour.
However, absolutely every POSIX-compliant shell I've tested implements the
local keyword, which lets you declare variables that won't be returned
from the current function. So nowadays you can safely count
on it working. Here's an example of the standard variable scoping:
func()
{
X=5
local Y=6
}
X=1
Y=2
(func)
echo $X $Y # returns 1 2; parens throw away changes
func
echo $X $Y # returns 5 2; X was assigned globally
Don't be afraid of the 'local' keyword. Pre-POSIX shells might not have had it, but every modern shell now does.
(Note: stock ksh93 doesn't seem to have the 'local' keyword, at least on MacOS 10.6. But ksh differs from POSIX in lots of ways, and nobody can agree on even what "ksh" means. Avoid it.)
5. Multi-valued and temporary exports, locals, assignments
For historical reasons, some people are afraid of mixing "export" with assignment, or putting multiple exports on one line. I've tested a lot of shells, and I can safely tell you that if your shell is basically POSIX compliant, then it supports syntax like this:
export PATH="$PATH:/home/bob/bin" CHICKEN=5
local A=5 B=6 C="$PATH"
A=1 B=2
# sets GIT_DIR only while 'git log' runs
GIT_DIR=$PWD/.githome git log
Update 2011/03/23: Someone pointed out that 'export' and 'local' commands are not like plain variable assignment; you do need to be careful about quoting (in some shells, but not bash, sigh), so I've added quotes above.
Update 2011/03/23: Someone points out that the last example, temporary variable assignment, doesn't work if the command you're calling is a shell function or builtin; the assignment becomes permanent instead. It's unfortunate behaviour, but shells seems to at least be consistent about it.
6. Multi-valued function returns
You might think it's crazy that variable assignments by default leak out of the function where you assigned them. But it can be useful too. Normally, shell functions can only return one string: their stdout, which you capture like this:
X=$(func)
But sometimes you really want to get two values out. Don't be afraid to use globals to accomplish this:
getXY()
{
X=$1
Y=$2
}
testy()
{
local X Y
getXY 7 8
echo $X-$Y
}
X=1 Y=2
testy # prints 7-8
echo $X $Y # prints 1-2
Did you catch that? If you run 'local X Y' in a calling function, then when a subfunction assigns them "globally", it still only affects your local ones, not the global ones.
7. Avoiding 'set -e'
The set -e command tells your shell to die if a function returns
nonzero in certain contexts. Unfortunately, set -e does seem to be
implemented slightly differently between different POSIX-compliant shells.
The variations are usually only in weird edge cases, but it's sometimes not
what you want. Moreover, "silently abort when something goes wrong" isn't
always the goal. Here's a trick I learned from studying the git source
code:
cd foo &&
make &&
cat chicken >file &&
[ -s file ] ||
die "resulting file should have nonzero length"
(Of course you'll have to define the "die" function to do what you want, but that's easy.)
This is treating the "&&" and "||" (and even "|" if you want) like different kinds of statement terminators instead of statement separators. So you don't indent lines after the first one any further, because they're not really related to the first line; the && terminator is a statement flow control, not a way to extend the statement. It's like terminating a statement with a ; or &. Each type of terminator has a different effect on program flow. See what I mean?
It takes a little getting used to, but once you start writing like this, your shell code starts getting a lot more readable. Before seeing this style, I would tend to over-indent my code, which actually made it worse instead of better.
By the way, take special note of the way we used the higher precedence of && vs || here. All the && statements clump together, so that if any of them fail, we fall back to the other side of the || and die.
Oh, as an added bonus, you can use this technique even if set -e is in effect: capturing the return value using && or || causes set -e to not abort. So this works:
set -e
mv file1 file2 || true
echo "we always run this line"
Even if the 'mv' command fails, the program doesn't abort. (Because this technique is available, redo always runs all its scripts with set -e active so it can be more like make. If you don't like it, you can simply catch any "expected errors" as above.)
8. printf as an alternative to echo
The "echo" command is chronically underspecified by POSIX. It's okay for simple stuff, but you never know if it'll interpret a word starting with dash (like -n or -c) as an option or just print it out. And ash/dash/busybox/ksh, for example, have a weird "feature" where echo interprets "echo \n" as a command to print a newline. Which is fun, except other shells don't do that. (zsh does, in zsh mode, but not in sh mode.) The others all just print backslash followed by n. (Update 2011/02/28: changed list of which shells do what with \n.)
There's good news, though! It turns out the "printf" command is available everywhere nowadays, and its semantics are much more predictable. Of course, you shouldn't write this:
# DANGER! See below!
printf "path to foo: $PATH_TO_FOO\n"
Because $PATH_TO_FOO might contain variables like %s, which would confuse printf. But you can write your own version of echo that works just how you like!
echo()
{
# remove this line if you don't want to support "-n"
[ "$1" = -n ] && { shift; FMT="%s"; } || FMT="%s\n"
printf "$FMT" "$*"
}
9. The "read" command is crazier than you think
This is both good news and bad news. The "read" command actually mangles its input pretty severely. It seems the "-r" option (which turns off the mangling) is supported on all the shells that I've tried, but I haven't been able to find a straight answer on this one; I don't think -r is POSIX. But if everyone supports it, maybe it doesn't matter. (Update 2011/02/28: yes, it's POSIX. Thanks to Alex Bradbury for the link.)
The good news is that the mangling behaviour gives you a lot of power, as
long as you actually understand it. For example, given this input file,
testy.d (produced by gcc -MD -c testy.c):
testy.o: testy.c /usr/include/stdio.h /usr/include/features.h \
/usr/include/sys/cdefs.h /usr/include/bits/wordsize.h \
/usr/include/gnu/stubs.h /usr/include/gnu/stubs-32.h \
/usr/lib/gcc/i486-linux-gnu/4.3.2/include/stddef.h \
/usr/include/bits/types.h /usr/include/bits/typesizes.h \
/usr/include/libio.h /usr/include/_G_config.h
/usr/include/wchar.h \
/usr/lib/gcc/i486-linux-gnu/4.3.2/include/stdarg.h \
/usr/include/bits/stdio_lim.h \
/usr/include/bits/sys_errlist.h
You can actually read all that content like this:
read CONTENT <testy.d
...because the 'read' command understands backslash escapes! It removes the backslashes and joins all the lines into a single line, just like the file intended.
And then you can get a raw list of the dependencies by removing the target filename from the start:
DEPS=${CONTENT#*:}
Until I discovered this feature, I thought you had to run the file through sed to get rid of all the extra junk - and that's one or more extra fork/execs for every single run of gcc. With this method, there's no fork/exec necessary at all, so your autodependency mechanism doesn't have to slow things down.
10. Reading/assigning a variable named by another variable
Say you have a variable $V that contains the name of another variable, say
BOO, and you want to read the variable pointed to by $V, then do a
calculation, then write back to it. The simplest form of this is an append
operation. You can't just do this:
# Doesn't work!
$V="$$V appended stuff"
...because "$$V" is actually "$$" (the current process id) followed by "V". Also, even this doesn't work:
# Also doesn't work!
$V=50
...because the shell assumes that after substitution, the result is a command name, not an assignment, so it tries to run a program called "BOO=50".
The secret is the magical 'eval' command, which has a few gotchas, but if you know how to use it exactly right, then it's perfect.
append()
{
local tmp
eval tmp=\$$1
tmp="$tmp $2"
eval $1=\$tmp
}
BOO="first bit"
append BOO "second bit"
echo "$BOO"
The magic is all about where you put the backslashes. You need to do some of the $ substitutions - like replacing "$1" with "BOO" - before calling eval on the literal '$BOO'. In the second eval, we want $1 to be replaced with "BOO" before running eval, but '$tmp' is a literal string parsed by the eval, so that we don't have to worry about shell quoting rules.
In short, if you're sending an arbitrary string into an eval, do it by setting a variable and then using \$varname, rather than by expanding that variable outside the eval. The only exception is for tricks like assigning to dynamic variables - but then the variable name should be controlled by the calling function, who is presumably not trying to screw you with quoting rules.
Update 2011/02/28: someone on reddit complained that the above code uses quoting incorrectly and is insecure. It isn't, assuming the first parameter to append() is a real variable name that doesn't contain spaces and control characters. This is a fair assumption, as long as you the programmer are the one providing that string. If not, you have a security hole, with or without quotes, exactly as if you allowed a user to provide the format string to printf. Don't do that then! Conversely, the second parameter to append is completely safe no matter what it contains. That's the one you'd expect to let users provide. So I really don't understand the security complaints here.
All that said, do be very very careful with eval. If you don't know what you're doing, you can hurt yourself.
11. "read" multiple times from a single input file
This problem is one of the great annoyances of shell programming. You might be tempted to try this:
(read x; read y) <myfile
But it doesn't work; the subshell eats the variable definitions. The following does work, however, because {} blocks aren't subshells, they're just blocks:
{ read x; read y; } <myfile
Unfortunately, the trick doesn't work with pipelines:
ls | { read x; read y; }
Because every sub-part of a pipeline is implicitly a subshell whether it's inside () or not, so variable assignments get lost.
Update 2011/03/23: Someone adds that you can't depend on this not working; in some shells, the above command will actually assign x and y as you want. But it doesn't work in most shells, so don't do it.
A temp file is always an option:
ls >tmpfile
{ read x; read y; } <tmpfile
rm -f tmpfile
But temp files seem rather inelegant, especially since there's no standard way to make well-named temp files in sh. (The mktemp command is getting popular and even appears in busybox nowadays, but it's not everywhere yet.)
Update 2011/02/28: andresp on reddit contributed a better suggestion than the following crazy one! See below.
Alternatively you can capture the entire output to a variable:
tmp=$(ls)
But then you have to break it into lines the hard way (using the eval trick from above):
nextline()
{
local INV=$1 OUTV=$2 IN= OUT= IFS= newline= rest=
eval IN=\$$INV
IFS=
newline="$(printf "\nX")"
newline=${newline%X}
[ -z "$IN" ] && return 1
rest=${IN#*$newline}
if [ "$rest" = "$IN" ]; then
# no more newlines; return remainder
eval $INV= $OUTV=\$rest
else
OUT=${IN%$rest}
OUT=${OUT%$newline}
eval $INV=\$rest $OUTV=\$OUT
fi
}
tmp=$(echo "hello 1"; echo "hello 2")
nextline tmp x
nextline tmp y
echo "$x-$y" # prints "hello 1-hello 2"
Okay, that's a little ugly. But it works, and you can steal the nextline function and never have to look at it again :) You could also generalize it into a "split" function that can split on any arbitrary separator string. Or maybe someone has a cleaner suggestion?
Update 2011/02/28: andresp on reddit suggests doing this instead. It works!
{ read x; read y; } <<EOF
$(ls)
EOF
Parting Comments
I just want to say that sh is a real programming language. When you're writing shell scripts, try to think of them as programs. That means don't use insane indentation; write functions instead of spaghetti; spend some extra time learning the features of your language. The more you know, the better your scripts will be.
When early versions of git were released, they were mostly shell scripts. Large parts of git (like 'git rebase') still are. You can write serious code in shell, as long as you treat it like real programming.
autoconf scripts are some of the most hideous shell code imaginable, and I'm afraid a lot of people nowadays use them to learn how to program in sh. Don't use autoconf as an example of good sh programming! autoconf has two huge things working against it:
-
It was designed about 20 years ago, long before POSIX was commonly available, so they avoid using really critical stuff like functions. Imagine trying to write a readable program without ever breaking it into functions! That hasn't been necessary for decades.
-
Because of that, ./configure scripts are generated by macro expansion (a poor person's functions), so ./configure is more like compiler output than something any real programmer would write. It's ugly like most compiler-generated code is ugly.
autoconf solves a lot of problems that have not yet been solved any other way, but it comes with a lot of historical baggage and it leaves a broken window effect. Please try to hold your shell code to a higher standard, for the good of all of us. Thanks.
Bonus: What shell should I use?
Update 2011/02/28: A strangely large number of people seem to think this article is recommending that you use bash for some reason. I like bash, it's a good shell. But the whole point of this article is exactly the opposite: that any POSIX shell can do a bunch of good things (like everything listed here), and you should avoid using bash-specific features.
If you want to help yourself avoid portability problems, I recommend using ash, dash, or busybox (which are all variants of the 'ash' shell) in your scripts. They're deliberately minimalist shells that try not to have any extra nonstandard features. So if it works in dash, it probably works in most other POSIX shells too. Conversely, if you test in bash, you'll probably accidentally use at least one bashism that makes your script incompatible with other shells. (The most common bashism is to use "==" instead of "=" in comparisons. Only the latter is in POSIX.)
Footnote
1 Of course, finding a shell with POSIX compliance is rather nebulous. The reason autoconf 'configure' scripts are so nasty, for example, is that they didn't want to depend on the existence of a POSIX-compliant shell back in 1992. On many platforms, /bin/sh is anything but POSIX compliant; you have to pick some other shell. But how? It's a tough problem. redo tests your locally-installed shells and picks one that's a good match, then runs it in "sh mode" for maximum compatibility. It's very refreshing to just be allowed to use all the POSIX sh features without worrying. By the way, if you want a portable trying-to-be-POSIX shell, try dash, or busybox, which includes a variant of dash. On really ancient Unixes without a POSIX shell, it makes much more sense to just install bash or dash than to forever write all your scripts to assume it doesn't exist.
"But what about Windows?" I can hear you asking. Well, of course you already know about Cygwin and MSys, which both have free ports of bash to Windows. But if you know about them, you probably also know that they're gross: huge painful installation processes, messing with your $PATH, incompatible with each other, etc. My preference is the busybox-w32 (busybox-win32) project, which is a single 500k .exe file with an ash/dash-derived POSIX-like shell and a bunch of standard Unix utilities, all built in. It still has a few bugs, but if we all help out a little, it could be a great answer for shell scripting on Windows machines.
Why would you follow me on twitter? Use RSS.