
2016-04-01 »
So last night I was thinking, hey, I work at a big company. People at big companies make their own TCP congestion control algorithms. Therefore, I can make my own TCP congestion control algorithm. And boy was I right!(!)
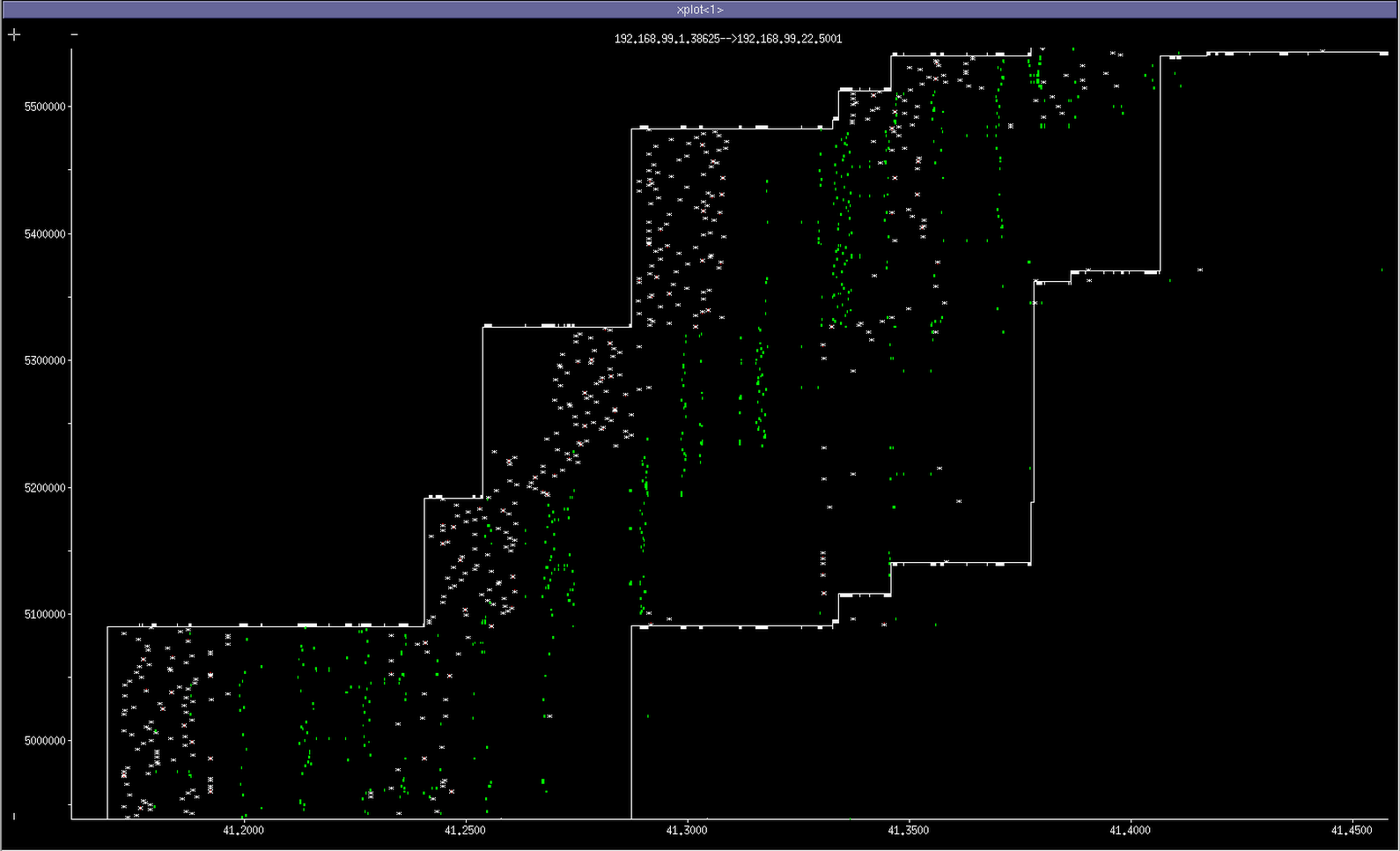
My contribution is TCP THERMAL (in all caps because the best congestion algorithms are named in all caps). It's named after the fact that if you use it, it will set your network on fire. Also, its tcp traces (pictured here) look a bit like what I imagine thermal noise looks like, if you could visualize it, and your visualization tool involved feeding said thermal noise into the cwnd estimator of a TCP flow.
Anyway, check out this magnificent concoction. Not a single byte of rwnd wasted! (The green dots are SACKs, and the white x's are transmitted or retransmitted packets. The top and bottom lines show the how the receive window progresses.)
...So okay, anyone familiar with TCP traces knows that this looks absolutely awful. But there's a method to my madness. What I actually did was I disabled congestion control entirely(!!), which is a stupid thing to do in the general case, but can actually help if you're on a local network, there are few traffic competitors, you don't want to compete fairly, you have a self-limited-rate stream (like video), and you have a horrible level of packet loss and latency. In this example, I made a bad 1x1 2.4 GHz wifi link with added 10% loss and 10 +/- 10ms of added latency. The idea is to make wireless TV work really well on really poor links.
In my test, THERMAL can still extract the benefit of about 60% of the link, while CUBIC collapses to less than 10%. (This picture is a worst-case from just running iperf at maximum speed. If you're streaming below the maximum, no, it doesn't look nearly this dumb.)
(!) I didn't say I could make a good TCP congestion control algorithm.
(!!) No matter what I do to the congestion control plugin, Linux's TCP still wants to back off the cwnd when it is retrying due to packet loss; I guess retries don't count as "congestion control" once you get past a certain desperation point. With high latency and loss, this results in very disappointing totally empty periods in the transmission (not shown here), where there is plenty of rwin left and we could be blasting future data even while waiting for the last few retries of previously-sent data. I can't figure out a way to disable this behaviour without modifying the kernel proper rather than just adding a new congestion module. Did I miss something?
Why would you follow me on twitter? Use RSS.