
2017-07-03 »
PyNitLog
Hello everyone! After many years of using a massively hacked-up version of dcoombs's NITLog page generator to host these pages, I've become, er, concerned, about the security of the ancient version of PHP I was using to host it. I tossed the whole thing out and rewrote it in python. The new thing doesn't really have a name, but let's call it PyNitLog.
My, how the web has moved on in the last 13 years or so! Now we can do all that stuff we used to do, but in a total of 298 lines of actually manageable code, including templates, and with hardly any insane regexes. Most of the credit goes to the python tornado library, which makes it really easy to write small, fast, secure web apps, even if you're super lazy.
Please let me know if anything explodes.
2017-07-04 »
Avery's[1] laws[2] of wifi reliability
Replacing your router:
Vendor A: 10% broken
Vendor B: 10% broken
P(both A and B broken):
10% x 10% = 1%
Replacing your router (or firmware) almost always fixes your
problem.
|
Adding a wifi extender:
Router A: 90% working
Router B: 90% working
P(both A and B working):
90% x 90% = 81%
Adding an additional router almost always makes things worse.
|
All wireless networks, both LTE and mesh, go down sometimes, but I'm willing to bet that your wifi network is flakier than your phone's LTE connection. At Battlemesh v10, we were all sitting in a room with dozens of experimental misconfigured wifi routers offering open networks that may or may not ever successfully route back to the real Internet. What makes a network reliable or unreliable?
After a few years of messing with this stuff (and being surrounded by tons of engineers working on other distributed systems problems, which turn out to all have similar constraints), I think I can summarize it like this. Distributed systems are more reliable when you can get a service from one node OR another. They get less reliable when a service depends on one node AND another. And the numbers combine multiplicatively, so the more nodes you have, the faster it drops off.
For a non-wireless example, imagine running a web server with a database. If those are on two computers (real or virtual), then your web app goes down if you don't have the web server AND the database server working perfectly. It's inherently less reliable than a system that requires a web server, but does not require a database. Conversely, imagine you arrange for failover between two database servers, so that if one goes down, we switch to the other one. The database is up if the primary server OR the secondary server is working, and that's a lot better. But it's still less reliable than if you didn't need a database server at all.
Let's take that back to wifi. Imagine I have a wifi router from vendor A. Wifi routers usually suck, so for the sake of illustration, let's say it's 90% reliable, and for simplicity, let's define that as "it works great for 90% of customers and has annoying bugs for 10%." 90% of customers who buy a vendor A router will be happy, and then never change it again. 10% will be unhappy, so they buy a new router - one from vendor B. That one also works for 90% of people, but if the bugs are independent, it'll work for a different 90%. What that means is, 90% of the people are now using vendor A, and happy; 90% of 10% are now using vendor B, and happy. That's a 99% happiness rate! Even though both routers are only 90% reliable. It works because everyone has the choice between router A OR router B, so they pick the one that works and throw away the other.
This applies equally well to software (vendor firmware vs openwrt vs tomato) or software versions (people might not upgrade from v1.0 to v2.0 unless v1.0 gave them trouble). In our project, we had a v1 router and a v2 router. v1 worked fine for most people, but not all. When v2 came out, we started giving out v2 routers to all new customers, but also to v1 customers who complained that their v1 router had problems. When we drew a graph of customer satisfaction, it went up right after the v2 release. Sweet! (Especially sweet since the v2 router was my team's project :)). Upgrade them all, right?
Well, no, not necessarily. The problem was we were biasing our statistics: we only upgraded v1 users with problems to v2. We didn't "upgrade" v2 users with problems (of course there were some) to v1. Maybe both routers were only 90% reliable; the story above would have worked just as well in reverse. The same phenomenon explains why some people switch from openwrt to tomato and rave about how much more reliable it is, and vice versa, or Red Hat vs Debian, or Linux vs FreeBSD, etc. This is the "It works for me!" phenomenon in open source; simple probability. You only have an incentive to switch if the thing you have is giving you a problem, right now.
But the flip side of the equation is also true, and that matters a lot for mesh. When you set up multiple routers in a chain, now you depend on router A AND router B to both work properly, or your network is flakey. Wifi is notorious for this: one router accepts connections, but acts weird (eg. doesn't route packets), and clients still latch onto that router, and it ruins it for everyone. As the number of mesh nodes increases, the probability of this happening increases fast.
LTE base stations also have reliability problems, of course - plenty of them. But they usually aren't arranged in a mesh, and a single LTE station usually covers a much larger area, so there are fewer nodes to depend on. Also, each LTE node is typically "too big to fail" - in other words, it will annoy so many people, so quickly, that the phone company will need to fix it fast. A single mesh node being flakey might affect only a smaller region of space, so that everyone passing through that area would be affected, but most of the time, they aren't. That leads to a vague impression of "wifi meshes are flakey and LTE is reliable", even if your own mesh link is working most of the time. It's all a game of statistics.
Solution: the buddy system
Let your friend tell you if you're making an ass of yourself.
Router A: 90% working
Router B: 90% working
P(either A or B working):
1 - (1-0.9) x (1-0.9) = 99%
|
In the last 15 years or so, distributed systems theory and practice have come a long way. We now, mostly, know how to convert an AND situation into an OR situation. If you have a RAID5 array, and one of the disks dies, you take that disk out of circulation so you can replace it before the next one dies. If you have a 200-node nosql database service, you make sure nodes that fail stop getting queries routed to them so that the others can pick up the slack. If one of your web servers gets overloaded running Ruby on Rails bloatware, your load balancers redirect traffic to one of the nodes that's less loaded, until the first server catches up.
So it should be with wifi: if your wifi router is acting weird, it needs to be taken out of circulation until it's fixed.
Unfortunately, it's harder to measure wifi router performance than database or web server performance. A database server can easily test itself; just run a couple of queries and make sure its request socket is up. Since all your web servers are accessible from the Internet, you can have a single "prober" service query them all one by one to make sure they're working, and reboot the ones that stop. But by definition, not all your wifi mesh nodes are accessible via direct wifi link from one place, so a single prober isn't going to work.
Here's my proposal, which I call the "wifi buddy system." The analogy is if you and some friends go to a bar, and you get too drunk, and start acting like a jerk. Because you're too drunk, you don't necessarily know you're acting like a jerk. It can be hard to tell. But you know who can tell? Your friends. Usually even if they're also drunk.
Although by definition, not all your mesh nodes are reachable from one place, you can also say that by definition, every mesh node is reachable by at least one other mesh node. Otherwise it wouldn't be a mesh, and you'd have bigger problems. That gives us a clue for how to fix it. Each mesh node should occasionally try to connect up to one or more nearby nodes, pretending to be an end user, and see if it can route traffic or not. If it can, then great! Tell that node it's doing a great job, keep it up. If not, then bad! Tell that node it had better get back on the wagon. (Strictly speaking, the safest way to implement this is to send only "you're doing great" messages after polling. A node that is broken might not be capable of receiving "you're doing badly" messages. You want a watchdog-like system that resets the node when it doesn't get a "great!" message within a given time limit.)
In a sufficiently dense mesh - where there's always two or more routes between a given pair of nodes - this converts AND behaviour to OR behaviour. Now, adding nodes (ones that can decommission themselves when there's a problem) makes things more reliable instead of less.
That gives meshes an advantage over LTE instead of a disadvantage: LTE has less redundancy. If a base station goes down, a whole area loses coverage and the phone company needs to rush to fix it. If a mesh node goes down, we route around the problem and fix it at our leisure later.
A little bit of math goes a long way!
Not enough for you?
You can see my complete slides (pdf) about consumer wifi meshes (including detailed speaker notes) from Battlemesh v10 in Vienna, or watch my talk on Youtube:
Previously: my talk on wifi data collection and analytics.
Footnote
[1] These so-called "laws" are a special case of more general and thus more useful distributed systems theorems. But this is the Internet, so I picked my one special case and named it after myself. Go ahead, try and stop me.
[2] Laws may be different in your jurisdiction.
2017-07-06 »
There's something funny about the auto song recommendations in this Jay-Z owned music streaming service, but I can't quite put my finger on it.
2017-07-11 »
Tesla and "overnight success"
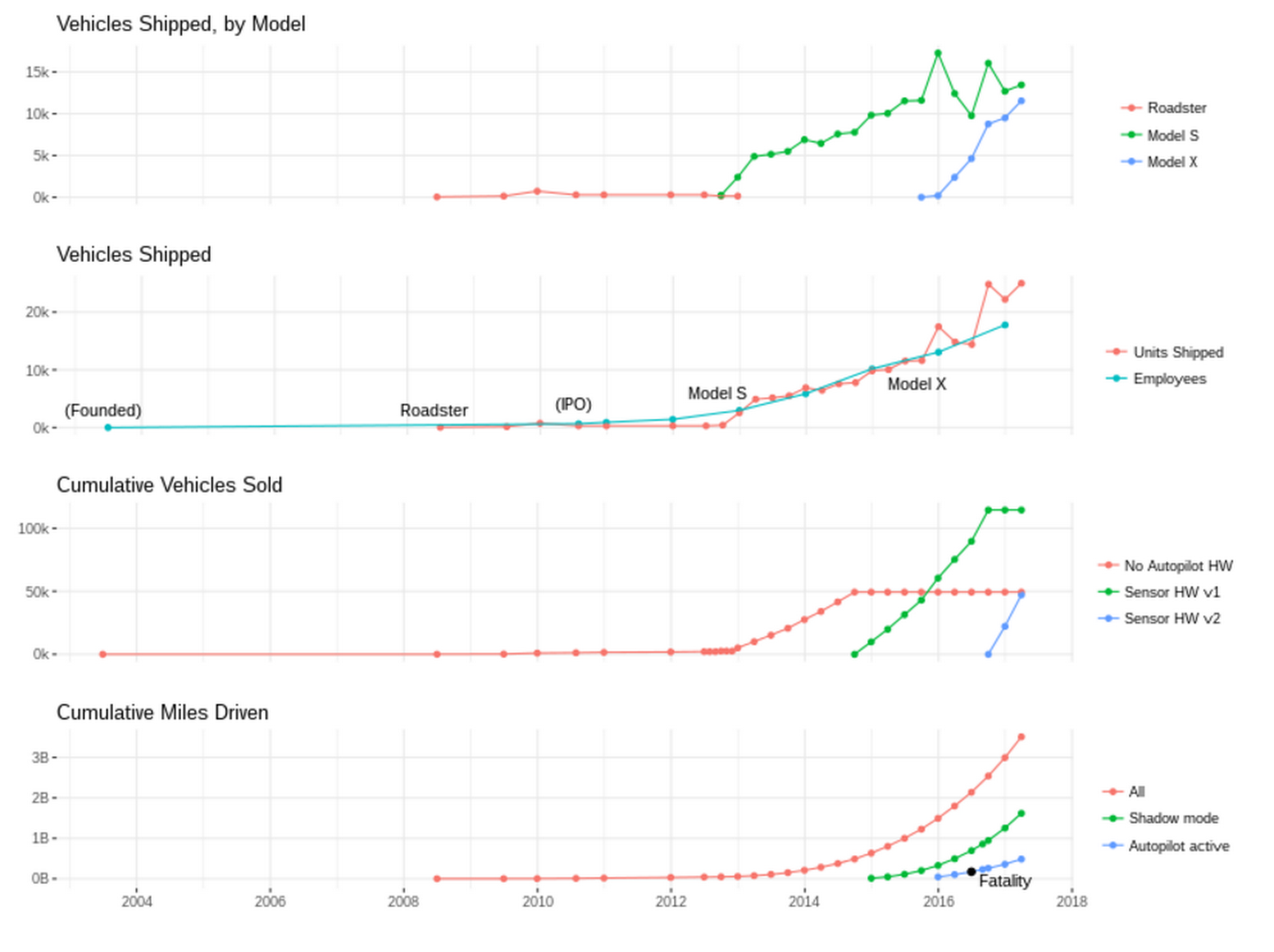
I've been thinking a lot about "overnight success" lately. Check out how long it's been taking for Tesla to achieve theirs! [Data collected by combining various public data sources. I might have screwed it up, but I think I'm mostly right.]
Of interest:
-
Wow, they really didn't sell very many Roadsters.
-
Recent increase in units/employee, probably due to better factory automation
-
Miles driven since the last (reported) autopilot fatality is more than 2x as many as before; they're either getting luckier or the software is getting better.
2017-07-12 »
I like that "99.9th percentile," while technically nonsense, is a concept we all readily understand.
2017-07-13 »
When I feel like being depressed, I measure time in units of Bachelor's degrees. For most impressive results, I simultaneously measure life experience in units of Bachelor's degrees.
Happy 1.5 billion seconds, everyone :)
2017-07-27 »
I'm continuing with my business book reading. One interesting concept I've just learned is the idea of "capabilities" (a pretty weird name, but the standard name, for this concept). There are three kinds of business capabilities: resources ("what"), processes ("how"), and priorities ("why").
Ignoring the awkwardness of calling people "resources," in this framework, resources include people, knowledge, and physical assets (like data centers for example). Resources are what finance types tend to do their accounting based on, including when they say "people are our most valuable resource," which is an entirely true statement, especially in a software company.
But most people don't account for processes and priorities when doing evaluations. Non-resource capabilities are very valuable. If you took the same people, removed them from their company, put them in a startup, and let them do whatever they want, that startup would not make nearly as much money as at their original company, at least not for a long time. The reason is that a big company has many processes (how do I get code deployed at scale? how do I decide how much to pay people? how does someone become a manager?) that, as much as we complain, mostly work okay. We also have a system for prioritizing projects and tasks and spending that, as much as we complain, also works okay (in that it prioritizes selling ads which then make a lot of money).
There are many companies without nearly the level of resources of a big company, that do quite well. The trick is that they make more out of those resources, using better processes and better prioritization. Because a big company has huge resources, they can afford to be worse at the other things.
And that's why it's possible for startups to have so little money and still outdo the big companies at some kinds of projects. Processes and priorities are cheap compared to resources, but you can't just buy them. They take a long time to form, and to change when you realize you have the wrong ones.
Why would you follow me on twitter? Use RSS.