
2016-06-28 »
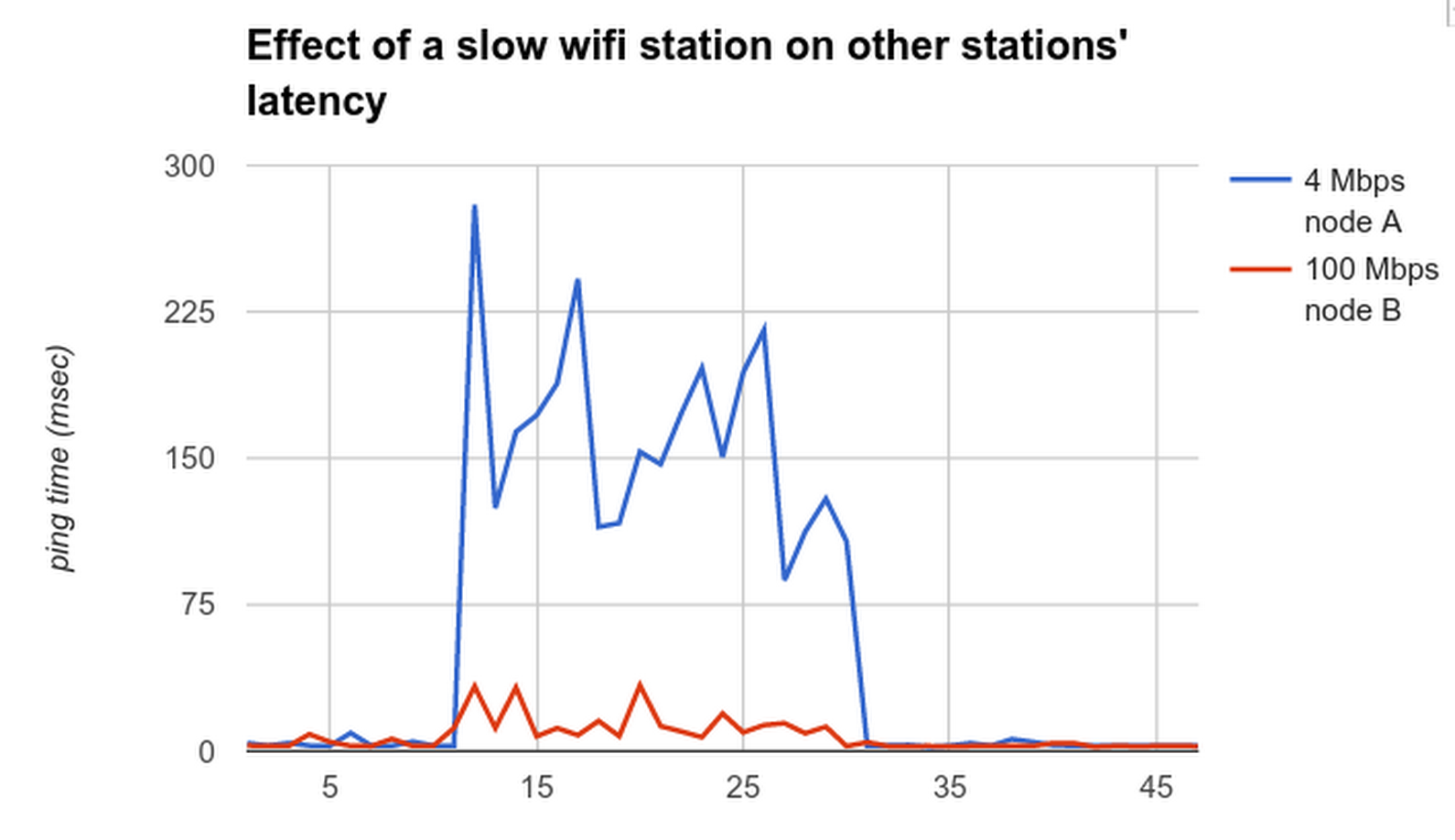
This graph may not look like much, but it's a pretty huge achievement, resulting from the work of several different people over 2+ years. In the test, there are two wifi stations: A, which is slow (low signal), and B, which is fast (good signal). Both are downloading data as fast as they can, so the AP's transmit queue is full. (We aren't lucky enough to be downloading from a server that uses, say, TCP BBR, so it just floods the transmit queue.)
In the old Linux kernel, all the traffic for both stations would be dumped into a single transmit queue, so traffic for both stations could be caught behind a big blob of traffic from the very slow node A. Thus, node B's latency would be fine right up until node A got busy, at which point, both nodes' latency would skyrocket. This is havoc for any kind of real-time streaming, such as Hangouts, GVC, or video game streaming.
With the recent set of patches now going into Linux, we divide up the wifi tx queue per station, then retrieve data round-robin from each of the queues. This has two effects: node A's impact on B's latency is much less (shown here), and nodes A and B get equal airtime rather than equal bytes (called airtime fairness, not shown here). Notably, this means there is now almost no benefit to "boosting" streams based on user input or heuristics, because all the streams get good results.
$VENDOR once came to us and did a demo of why you need three radios, so you can put low-end clients into the "penalty box" channel so they can't ruin performance for high-end clients. Of course, they wanted to sell more chips. These patches solve the software problem in software instead, where it belongs, at no extra cost.
This graph is a major improvement over what you'd see with the old way of doing things, but there are still two problems: a) node B is still perturbed more than it should be. We believe this is just a bug in ath9k (too-large hardware queue in the no-aggregation case) that we can probably fix soon, so the induced latency should be max ~12ms rather than the current max ~35ms, and usually much less. And b) node A's own self-induced latency needs to be controlled. Michal Kazior actually has a patch for this, to apply fq_codel to each station's subqueue, thus keeping its own latency under control. However, I don't trust that patch yet, as fq_codel is rather fiddly and was not designed for wifi's variability, so we haven't applied it to our kernel as is.
Known contributors: Felix Fietkau, Michal Kazior, Toke Høiland-Jørgensen, Tim Shepard, Dave Taht, Andrew Mcgregor, Eric Dumazet, Johannes Berg.
I would like to claim credit for any of this, but the truth is I mostly just evangelized at a lot of people until they eventually did what I wanted, whether or not it was causally related to said evangelization. I guess we'll never know. Oh well, mission accomplished! [1]
[1] in the style of George W. Bush. This is still wifi after all.
Why would you follow me on twitter? Use RSS.