
2007-08-04 »
Desktop applications are dead?
I've posted before about the general crapulence of the Web 2.0 movement, but here's an excellent counterpoint: Desktop Applications are Dead. Instead of listing the reasons why web applications are better than desktop applications (they mostly aren't, at least not inherently), he describes how desktop applications have been getting worse. Well said.
2007-08-06 »
Aiee, Robot!
I came home to visit my family for the weekend and, as usual, we got up to some exciting activities. The project this time: revive my ancient Robie Sr. robot (a relative of the Omnibot), a treasured toy from my childhood in the 1980's, and "modernize" him a bit.

Robie's troubles started about 17 years ago when his battery (a giant 6V lead-acid type) died. At the time, a replacement was prohibitively expensive (possibly because I was 12). But to my surprise, the model of battery they used still exists and my dad picked up a replacement this summer on a trip to the U.S. A few hours of charging, and Robie was back in action.
But as cool as a factory-standard Robie is, he's pretty limited by modern standards. At the time, it was cool: you could record a program onto a cassette tape (young'uns, see here) and play it back, and he'd do what you programmed him to. The program was an extremely basic form of frequency shift keying where there was one frequency for each button on the remote control, and the sound would be emitted from the remote for as long as you held down the button or pulled the joystick in a particular direction.

From 1980's control...
I'd always been fascinated by the control system, because it was so easy to understand: the remote control would form the sounds it wanted to send, then modulate them to 49 MHz FM (the usual frequency used by consumer remote-control devices). The robot would receive the signal, demodulate it back to listenable sounds, then recognize the different frequencies. In the case of a tape program, it would simply skip the modulation/demodulation steps and process the sounds directly from the tape.
That remote control mechanism is still (very much to my dismay) exactly how most remote control devices work to this day. But the tape mechanism is officially outdated. You can't really expect me to reprogram my robot by recording an audiocassette, can you? I don't even have any audiocassettes. And how could I possibly connect that to the internet? Ridiculous.
But at the same time, I only have one 1980's robot (with high sentimental
value) and one remote control, so I don't want to go fiddling inside either
of them and risk ruining them. What to do?

...to 1990's control...
As it happened, from around the same time in my life, I had a set of two walkie-talkie devices that broadcast and received on the same frequency as Robie. You can imagine that I spent hours of my childhood listening to my robot control sounds coming through a walkie talkie, which is how I came to understand this stuff in the first place. The walkie talkies had a small amount of sentimental value, but weren't worth worrying about. So my dad disconnected the microphone and replaced it with an audio jack, thus allowing us to transmit whatever signal we wanted over the airwaves to control Robie. (Most of my hardware rewiring stories seem to end up with my dad soldering something. Apparently I'm lazy. Anyway, note the neat switch on the back that could re-enable the microphone, and how nicely the audio jack has been installed. Also note the newly-added clip on the side that allows you to lock in the transmit button.)
Round 1 of our upgrade was to bring the system firmly into the 90's. We downloaded a .wav recording of Robie's original demo tape (it's important to use plain .wav format, as mp3 compression risks disrupting the pure signal) and burned it to a CD. Ta da! No more need for the cassette player.

...and into the 21st century
And at last, the most exciting step: once you have a digital file and the ability to transmit from any audio equipment you want, the real answer is clear: computer control! While "watching" Bridge to Terabithia, I whipped up an application in Delphi in about an hour, thanks to the TJvWavePlayer component in the awesome open source JVCL library.

Success! After clicking the "Sound On" button, any sound from my computer can now be beamed into Robie, so I can have him move around and play astonishingly-low-fidelity MP3s at people!
Then my sister correctly pointed out that we could integrate something like Festival speech synthesis: enter a string into the UI, synthesize it, and send it to Robie's sound unit. A talking 1980's robot! Now that's an upgrade.

...that is, until I get me a wireless webcam.
Parting note
I'm not crazy. You're crazy.
2007-08-08 »
The Nitix Bunny
At last, a long-awaited photo of an infamous Nitix bunny. I gave away all my own bunnies before I was smart enough to take a photo of them, but since I've been back home lately anyway, here's the one I gave to my sister last year.

2007-08-09 »
Death by statistics
The ever-insightful Pmarca writes about Age and the entrepreneur, mostly quoting from historical research by Dean Simonton at UC Davis.
This topic is very close to my heart, as I'm currently at the exact age where genius-programmer productivity is rumoured to fall off, and I'm recently left my first startup and joined/co-founded/spunoff/?? a second one. What does that mean for the success of my new company?
Without drawing any conclusions about that for now - maybe some other time - I'd just like to point out that some of Pmarca's interpretation of the data is slightly wrong. He seems to make the mistake of confusing statistical averages with individual cases. For example,
- Simonton: Indeed, because an earlier productive optimum means that a writer can
die younger without loss to his or her ultimate reputation, poets exhibit a
life expectancy, across the globe and through history, about a half dozen
years less than prose writers do.
Pmarca: You know what that means -- if you're going to argue that younger
entrepreneurs have a leg up, then you also have to argue that they will have
shorter lifespans. Fun with math!
This may just be a joke, but it warrants clarification anyway: Simonton has just pointed out a mathematical fact, not a statistic. Imagine a particular creative genius dies at age 40. If he was a poet, he was already past his productive peak, so he'll be famous anyway; if he was a novelist, he hadn't hit his peak yet, so he probably won't be famous. If you take a bunch of people like this and let them all die at random ages, but we know that novelists tend to peak later in life than poets, then your sample set of famous novelists will necessarily have more long-lived people than your sample set of poets. It's just a statistical bias. No, peaking earlier doesn't make you die sooner. Of course not.
Here's a more important but less obvious example:
- Simonton: Another way of saying the same thing is to note that the
"quality ratio," or the proportion of major products to total output per age
unit, tends to fluctuate randomly over the course of any career. The quality
ratio neither increases nor decreases with age...
Pmarca: Quality of output does not vary by age... which means, of course,
that attempting to improve your batting average of hits versus misses is a
waste of time as you progress through a creative career.
Youch! Once again, the statistics of the average group don't define the behaviour of an individual; that's backwards! Think of it this way: even if each person's "quality ratio" is completely random, what are the chances that nobody's quality ratio trends upwards throughout their life? Almost zero. What are the chances that nobody's quality ratio trends upwards dramatically as their life goes on? Very low. It's just another mathematical fact - if there's any particular pattern that's especially unlikely, then your data isn't really random. (And data that's not really random has a cause, which means you can improve it.)
What Simonton is saying is that there's no overall trend; statistically speaking, you're just as likely to get worse as to get better... and some of the world's best creative geniuses have gotten worse over time, not better.
But that assumes your improvement is completely random - that is, out of your control, and based only on things you can't understand. Maybe some people are "natural" geniuses, and everything they try to do to make themselves better is misguided and just pollutes their natural genius. But maybe other people are naturally stupid, and through lifelong education and practice they manage to weed out the useless parts and fine-tune their skills. Isn't that more likely than that their improvement was "random" and someone just lucked out and got better over time, while another genius was just "unlucky" and got worse?
Let's put it this way: the average genius doesn't improve with age. Do you want to be just an average genius?
2007-08-10 »
Intelligent design
- "I have been asked to comment on whether the universe shows signs
of having been designed. I don't see how it's possible to talk about
this without having at least some vague idea of what a designer would
be like. Any possible universe could be explained as the work of some
sort of designer. Even a universe that is completely chaotic, without
any laws or regularities at all, could be supposed to have been
designed by an idiot."
-- Steven
Weinberg
2007-08-11 »
Things people forgot to link to
Hi there, Google?
Yeah, it's me. I know I don't really talk to you much anymore, but well... I guess we've both been busy. Besides, are you really listening anyway? You have to pay attention to all the billions of people in the world, why would you care about little ol' me and my problems? There are lots of people a lot worse off than me. So don't worry, I won't feel bad if you don't have time for me, I can respect that.
Look at me, prattling on. I guess it's because all our conversations are so... one-sided, you know? I don't get any feedback. I realize it's hard for you to get back to me - just listening to all those people talking to you must be hard enough, without trying to reply to every person individually. Also, I know you prefer to work indirectly. It's not like you're going to say, "Okay, Avery, I'll fix that right up!" - you'll just index things differently or adjust their PageRank or whatever it is that you do up there.
Anyway, let me get to the point. I want you to know that my friend wlach posted in his LiveJournal about his new pathfinder project, but forgot to actually link to it, so how would you know when you see it that it's the most important pathfinder, the RFC3280-compliant X509 CRL certificate validator in the whole world? It even uses WvStreams, which by the way is hosted at alumnit.ca now and not open.nit.ca as you seem to think.
Also, I want to talk to you about Jeff Brown. No, not that Jeff Brown, the other one. No, not that one either. See, that's what I want to talk to you about. I don't care about all those other Jeff Browns. This Jeff Brown is the Jeff Brown who used to work at NITI and contributed major portions of the UniConf design. I think he should really be at the top of Google listings for Jeff Brown so he's easier to find, don't you?
Well anyway, Google, if you're out there, thanks for listening. I know you'll do the right thing in the end. It's just so hard to just trust you and let things happen, you know?
2007-08-12 »
Stranger than fiction
The novel I wrote last November as part of NaNoWriMo was silly and largely pointless. (My favourite!) It included the concept of a race where people competed, not to get to the destination first, but to get the most publicity while doing so. The scoring system was a bit complex as monitoring all forms of media looking for mentions of a particular person, then scoring that person appropriately, was fairly difficult. So much for that.
<Rams head into wall>
I was kidding! Do I have to spell it out for you?
2007-08-13 »
In praise of the C preprocessor
Let's face it. cpp, the C preprocessor, gets a lot of flak among language designers. People blame it for all sorts of atrocities, including code that doesn't do what it says it does, weird side effects caused by double-evaluation of parameters, pollution of namespaces, slow compilations, and the generally annoying evil that is the whole concept of declaring your API in C/C++ header files.
All of these accusations are true. But there are some things you just can't do without it. Watch.
Example #1: doubling
Here's a typical example of why C/C++ preprocessor macros are "bad." What's wrong with this macro?
#define DOUBLE(x) ((x)+(x))
(Notice all the parens. Neophytes often leave those out too, and hilarity ensues when something like 3DOUBLE(4) turns into 34+4 instead of 3*(4+4).)
But the above macro has a bug too. Here's a hint: what if you write this?
y = DOUBLE(++x);
Aha. It expands to y=((++x)+(++x)), so x gets incremented twice instead of just once like you expected.
Macro-haters correctly point out that in C++ (and most newer C compilers), you can use an inline function to avoid this problem and everything like it:
inline double DOUBLE(double x) { return x+x; }
This works great, and look: I didn't need the extra parens either. That's because C++ language rules require the parameter to be fully evaluated first before we implement the function, whether it's inline or not. It would have been totally disastrous if inline functions didn't work like that.
Oh, but actually, that one function isn't really good enough: what if x is an int, or an instance of class Complex? The macro can double anything, but the inline can only double floating point numbers.
Never fear: C++ actually has a replacement macro system that's intended to obsolete cpp. It handles this case perfectly:
template<typename T>
inline T DOUBLE(T x) { return x+x; }
Cool! Now we can double any kind of object we want, assuming it supports the "+" operation. Of course, we're getting a little heavy on screwy syntax - the #define was much easier to read - but it works, and there are never any surprises no matter what you give for "x".
Example #2: logging
In the above example, C++ templated inline functions were definitely better than macros for solving our problem. Now let's look at something slightly different: a log message printer. Which of the following is better, LOGv1 or LOGv2?
#define LOGv1(lvl,str) do { \
if ((lvl) <= _loglevel) print((str)); \
} while (0)
inline void LOGv2(int lvl, std::string str)
{
if (lvl <= _loglevel) print(str);
}
(Trivia: can you figure out why I have to use the weird do { } while(0) notation?)
Notice that the problem from the first example doesn't happen here. As long as you only refer to each parameter once in the definition, you're okay. And you don't need a template for the inline function, because actually the log level is always an int and the thing you're printing is (let's assume) always a string. You could complain about namespace pollution, but they're both global functions and you only get them if you include their header files, so you should be pretty safe.
But my claim is that the #define is much better here. Why? Actually, for the same reason it was worse in the first example: non-deterministic parameter evaluation. Try this:
LOGv1(1000, hexdump(buffer, 10240));
Let's say _loglevel is less than 1000, so we won't be printing the message. The macro expands to something like
if (1000 <= _loglevel) print(hexdump(buffer, 10240));
So the print(), including the hexdump(), is bypassed if the log level is too low. In fact, if _loglevel is a constant (or a #define, it doesn't matter), then the optimizer can throw it away entirely: the if() is always false, and anything inside an if(false) will never, ever run. There's no performance penalty for LOGv1 if your log level is set low enough.
But because of the guaranteed evaluation rules, the inline function actually expands out to something like this:
std::string s = hexdump(buffer, 10240); if (1000 < _loglevel) print(s);
The optimizer throws away the print statement, just like before - but it's not allowed to discard the hexdump() call! That means your program malloc()s a big string, fills it with stuff, and then free()s it - for no reason.
Now, it's possible that C++ templates - being a full-powered macro system - could be used to work around this, but I don't know how. And I'm pretty smart. So it's effectively impossible for most C++ programmers to get the behaviour they want here without using cpp macros.
Of course, the workaround is to just type this every time instead:
if (1000 <= LOGLEVEL) LOGv2(hexdump(buffer,10240));
You're comparing to LOGLEVEL twice - before LOGv2 and inside LOGv2 - but since it's inline, the optimizer will throw away the extra compare. But the fact that one if() is outside the function call means it can skip evaluating the hexdump() call.
The fact that you can do this isn't really a justification for leaving out a macro system - of course, anything a macro system can do, I can also do by typing out all the code by hand. But why would I want to?
Java and C# programmers are pretty much screwed here(1) - they have no macro processor at all, and those languages are especially slow so you don't want to needlessly evaluate stuff. The only option is the explicit if statement every time. Blech.
Example #3: assert()
My final example is especially heinous. assert() is one of the most valuable functions to C/C++ programmers (although some of them don't realize it yet). Even if you prefer your assertions to be non-fatal, frameworks like JUnit and NUnit have their own variants of assert() to check unit test results.
Here's what a simplified assert() implementation might look like in C.
#define assert(cond) do { \
if (!NDEBUG && !(cond)) \
_assert_fail(__FILE__, __LINE__, #cond); \
} while (0)
We have the same situation as example #2, where if NDEBUG is set, there's no need to evaluate (cond). (Of course, exactly this lack of evaluation is what sometimes confuses people about assert(). Think about what happens with and without NDEBUG if you type assert(--x >= 0).)
But that's the least of our worries: I never use NDEBUG anyway.
The really valuable parts here are some things you just can't do without a preprocessor. FILE and LINE refer to the line where assert() is called, not the line where the macro is declared, or they wouldn't be useful. And the highly magical "#cond" notation - which you've probably never seen before, since it's almost, but not quite, never needed - turns (cond) into a printable string. Why would you want to do that? Well, so that you can have _assert_fail print out something awesome like this:
** Assertion "--x >= 0" failed at mytest.c line 56
Languages without a preprocessor just can't do useful stuff like that, and it's very bothersome. As with any macroless language, you end up typing it yourself, like in JUnit:
assertTrue("oh no, x >= 5!", --x >= 0);
As you can see in the above example, the message is usually a lie, leading to debugging wild goose chases. It's also a lot more typing and discourages people from writing tests. (JUnit does manage to capture the file and function, thankfully, by throwing an exception and looking at its backtrace. It's harder, but still possible, to get the line number too.)
Side note
(1) The C# language designers probably hate me, but actually there's nothing stopping you from passing your C# code through cpp to get these same advantages. Next time someone tells you cpp is poorly designed, ask yourself whether their "well-designed" macro language would let you do that.
2007-08-14 »
That was fast
Once upon a time, search engines could only crawl the internet every few months. Apparently that's no longer the case: after my polite request, the real Jeff Brown is already the top google hit for "Jeff Brown NITI." (Oddly, he's not the top hit for "jeff niti" though. Some random Jeff on MySpace seems to have a friend named niti. Or something. And apologies to jklink, who doesn't seem to have a web site.)
He's still only on page 2 of the "Jeff Brown" results, but that's not too bad, considering. At least he's findable now.
By the way, I hereby claim at least partial responsibility for the placement of the real Larry Smith in the search rankings. Shame his web site sucks so badly, though.
2007-08-15 »
Automake
- The default is to generate auto-tools based makefiles. It is recommended
that people with acid reflux, ulcers or other delicate stomach conditions
use the --simple-makefiles option. --simple-makefiles produces a configure
and Makefile script that are essentially the labor of love.
2007-08-16 »
More language wars
Despite my negative sounding comments in In praise of the C preprocessor, I actually really respect the design of the C# language. Here's another example of C#'s smart design via Raymond Chen.
The .net libraries are another story. They seem to have their very own Ulrich to work around. But I digress.
2007-08-20 »
A brief note on climate change... and objectivity
I normally don't stray too far from programming/business-related topics and I normally don't just link to news articles, but this one is too stupid to pass up: "Blogger proves NASA wrong on climate change."
Forget about the bloggers in the headline, I don't care. The actual article body says: after revising the statistics due to a calculation error (which NASA has now admitted making), we now see that five of the top 10 warmest years in recorded U.S. history occurred before 1939.
"Recorded history" means since about 1890 or so, which means that throughout U.S. recorded history, temperatures have trended up, then down, then up again, and are currently near the same level as in 1939.
Now let's look at the article. The person who found the error is obviously biased: he's a "former mining executive." Yet NASA updated their figures when he corrected them.
They sure downplayed it in their announcement: "...unless you are interested in temperature changes to a tenth of a degree over the US and a thousandth of a degree over the world."(1)
Well, actually, yes, I am interested in those changes, because a tenth of a degree is apparently all it takes to support or deny a claim of half-century-long global warming nowadays.
Look, this isn't science, it's propaganda. This is science:

Looks like it's trending... um, er, well, there's a whole scientific paper analyzing these results.(2) Have you read it? Do you understand it? If not, don't try to tell me about global warming.
I think polluting a little less is probably a good idea, even still. I don't need a scientist to tell me that smog smells bad.
In other news
Also, anybody who thinks the current price of gasoline has anything to do with "peak oil" does not understand economics.
Which is not to say we won't run out of oil, or that we're not evil polluting earth-destroying monsters, or that oil prices aren't high. But they were higher in 1979.
Footnotes
(1) If anyone can find a link to the actual press release/memo on an actual NASA site, I'd appreciate hearing about it.
(2) Cheater summary: after extensive numerical analysis, the paper says it's trending upward and has increased by about 0.5 degrees F (0.27 degrees C) since 1950. But you'll have to decide for yourself if their numerical analysis is correct, because they sure didn't just get out a ruler and draw a trendline.
2007-08-23 »
Misunderstanding Exceptions
- It is funny how people think that the important thing
about exceptions is handling them. That is not the important thing about
exceptions. In a well-written application there's a ratio of ten to one, in
my opinion, of try finally to try catch.
-- Anders
Hejlsberg, designer of Turbo Pascal, Delphi, and C#
2007-08-24 »
More on preprocessors
pcolijn points out that in my earlier article about the C preprocessor I missed an important part about Java logging, namely that you can delay expensive object-to-string computations until inside the function call itself, because your log function can take a bunch of Object elements as parameters.
That's actually a really neat trick that I hadn't thought of. In C++ it's hard to do because there's no common-to-everyone Object class with a toString() type method, and auto-casting everything into any kind of Object would be expensive.
Now, to get a hexdump() as in my specific example, you'd need to write some kind of HexDumper class with a toString() method that actually does the hexdump. It would be a little strange, but mostly harmless. The trick would work in C# too.
I mostly write this because the program I was debugging last night was written in C, but didn't use the preprocessor trick for its logging, so I ran into exactly the performance program I was talking about. Ha ha, very funny, universe.
2007-08-25 »
The power of stupid
- This story made me think about one of the great wonders of
capitalism: It is driven by morons who are circling the drain, and yet...
it works!
-- Scott Adams
For some reason I really like the imagery in that quote. I guess it reminds me of Web 2.0.
The rest of his article, "The Power of Stupid", is also pretty good.
2007-08-28 »
Versaplex
adewhurst finished his summer co-op term working with me at Versabanq last week, and this week I sorted out the necessary details to open source essentially all of his work (and the work I did to work with it). Yay!
The good news is it's a fun project that involves ODBC and middleware (I give up, I must be a middleware guy), and a port of dbus to WvStreams and of the latest WvStreams to Win32.
The bad news is that to build it all you currently need Ubuntu, experimental versions of mono and libdbus, an unreleased branch of WvStreams, and quite a lot of documentation that currently exists only in Adrian's head and mine.
So please don't think of this as an announcement, because if I were to announce the release right now, it would be a terrible disappointment to you since you could never possibly make it work.
Just think of it as another step in making banking fun. And look forward to the actual release announcement, coming soon.
2007-08-29 »
But... but... I like the Internet!
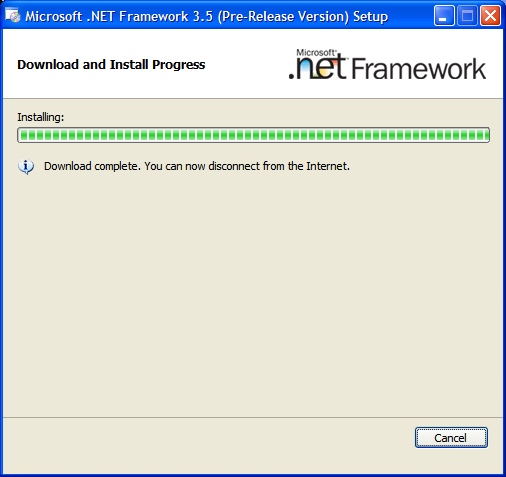
Bonus points:
When I press the "Cancel" button, it warns me that setup is not complete. Am I sure I really want to exit setup?
Well, actually, no. I wanted to install your program. That would be a good thing for you to do next.
Please?
2007-08-30 »
Longest keynote presentation evar
I don't know if it's an error in the programme or not, but this conference seems to have a keynote presentation that goes from 8:30am to 6:30pm.
It's the diametric opposite of 5-minute DemoCamp demos. Since it's about the details of treasury financing inside credit unions, I guess there's a reason they don't use the 5-minute format.
Why would you follow me on twitter? Use RSS.