
2007-09-01 »
Disturbing adventures in preprocessing, continued
I've been getting quite some interest in my earlier article, In praise of the C preprocessor. First, pcolijn wrote to point out that Java can delay evaluation of expensive toString() operations until later, so the cost of an unprinted log message can be pretty unimportant.
Then, fellow alumnit slajoie (I forgot how awesome his website was) wrote me to say that actually, the exact side-effect-reducing behaviour possible in C/C++ via the preprocessor was available in .Net due to a highly specific language feature:
using System; using System.Diagnostics;class Test { public int i = 1000;
[Conditional("FOO")] private void MaybeAdd(int incr) { i += incr; } private int SideEffect() { return ++i; } public static int Main(string[] args) { Test o = new Test(); Console.WriteLine("{0}", o.i); o.SideEffect(); Console.WriteLine("{0}", o.i); o.MaybeAdd(o.SideEffect()); Console.WriteLine("{0}", o.i); return 0; }}
Compile this with "csc foo.cs" (or use mono's gmcs) and run it, and you get "1000 1001 1001". But use "csc /d:FOO foo.cs" (or use gmcs) and you get "1000 1001 2004".
The magic "[Conditional]" attribute not only makes a function not get included if you leave out the define, but it makes the caller of the function not evaluate its parameters at all. They're still type-checked, however. And note the neat way in which you don't have to define both the normal and "empty" versions of MaybeAdd() - it's automatic.
This is used already by System.Diagnostics.Debug.Assert and the related Trace stuff, among other things.
The decision to implement a particular feature of the preprocessor via a specific language feature (instead of simply providing a generic solution like cpp) is an interesting one that C#/.Net takes in several other places too. For example, C# generics aren't nearly as powerful as C++ templates, but because they're tuned for a specific purpose (and #@%! function pointers aren't insane in C#, so you don't need them for that) they actually work much better than templates in C++.
UPDATE: Oh dear, the C# situation is even crazier than I thought. Apparently conditional attributes weren't enough for them. Now we have partial methods in which functions that are declared, but not defined, can be called without a problem but their parameters aren't even evaluated. I don't understand the explanation ("lightweight callbacks") for why this is useful, but I assume it must be, because it seems like way too much work to invent otherwise.
2007-09-03 »
More on expensive gasoline
In my article about climate change, I mentioned in passing that "anybody who thinks the current price of gasoline has anything to do with 'peak oil' does not understand economics." Now, to be fair, some people really don't understand economics, which I guess is actually to be expected if you haven't studied it.
But you really can't understand gas prices without it, so here we go with some ECON101.
Introduction to price optimization, without even using calculus
Let's say I'm a widget vendor in 1999, and my company is the only company able to make widgets. (Because of a monopoly, patents, whatever.) I'm selling widgets to you for $0.50 each, and people buy 1000 widgets this year. Now let's say, as an experiment, that I raise the price a bit each year, so that by 2007, widgets are $1 each, and because of the increased prices, people are now only willing to buy 750 widgets a year. Quiz time:
-
How much money did I make in 1999 vs. 2007?
-
Did I do the right thing by raising the price?
-
What does this say about the trends in worldwide widget production?
Answers:
-
$500 in 1999 and $750 in 2007 (or $625 in inflation-adjusted 1999 dollars).
-
Absolutely. You made more money, but wasted fewer worldwide resources and did less work, which means you could get away with hiring fewer people and therefore ditch some unproductive middle managers. If you hadn't had a monopoly, or people hadn't needed widgets so badly (less price elasticity), you might have been in more trouble.
-
As the only producer of widgets in the world, I will have reduced my production rate because I'm selling fewer widgets and I don't want to fill warehouses with extras - that costs me money. This doesn't mean the world is running out of widgets, it means I'm smart enough to cut the supply of widgets because I make more money that way.
And back to oil
Now replace "widgets" with "1L of gasoline in Canada" in the above example, and you have the story of the worldwide oil market.
The only difference is... did people really reduce their gasoline consumption to 75% of its initial value just because the price per litre doubled? Actually no, I just made that up. Here's what it actually looks like (the red line is U.S. oil consumption; the green (or is it black?) line is irrelevant for our purposes, but click the image if you're interested):
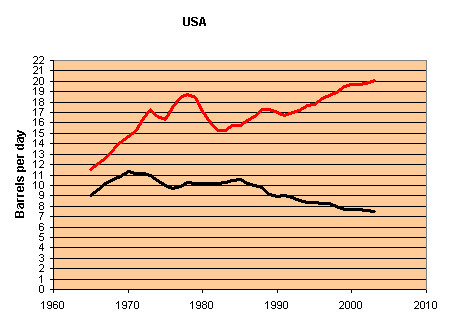
(It doesn't matter whether we graph supply or consumption; they'll be about the same, because as with widgets, nobody wants to keep around warehouses with billions of barrels of oil.)
Wouldn't you love to run a business where consumption goes up even though you doubled the price? Okay, actually, as wlach points out, consumption (production) has actually been flat for the last couple of years, suggesting that maybe prices are high enough now.
But just as a thought experiment, imagine that gas prices doubled one more time. Would you drive less than half as much as you do right now? Really? If not, it's in their best interests to do it all over again. And you'd surely see the production actually go into decline as they make more money while you buy less gas.
Oh yes, the world is running out of oil, all right. But that has nothing to do with its price.
2007-09-05 »
Making banking not fun
26 pages of pain about converting a project from MS SQL to PostgreSQL - one direction only. The document could be useful, if you find yourself stuck in such a situation, but it's also educational if you're interested (as I am) in how compatible different database systems are with each other. Answer: they aren't.
SQL today is in about the state that C was in in the early 1990's: implemented differently by lots of different low-quality vendors. People had to choose, then put up with, a different vendor's combination of features and misfeatures depending on their needs. Then Linux and gcc came along for free and set the bar for competition so high that we hardly remember there used to be a bar (or a market for non-Microsoft C compilers).
SQL today is also similar to 1990's C in that it's the best standard we've got, and the alternative pain we'd be in without it would be truly astonishing.
2007-09-07 »
Caffeine consumption
I'm quite enjoying these statistics-based posts I've been doing lately. And I just figured out why: because it's totally countercultural! If the whole world is running on idiotic rumours and half-baked opinions, it's kind of fun to do the exact opposite.
Today I have an easy one: people have often commented that even though I don't drink coffee, I get plenty of caffeine because I drink plenty of soft drinks, so I'm not really any different. My answer is always, "don't soft drinks have a lot less caffeine, though?" And then the conversation dies because nobody really knows.
Well, here's the answer: coffee has about 6.4 times as much caffeine per volume than coke. I don't drink 6.4 times as much coke as you drink coffee, that's for sure. Also, green tea has about 25% more caffeine than coke, but less sugar (unless you add it), so it's probably even less of an upper. Tazo Chai has about double that, or 1/3 as much as coffee.
And there's actual evidence that caffeine makes insomnia worse (surprise), so that could help explain why I sleep better than a lot of my friends.
On relative availability of information
The web contains about a zillion sources of information about how much caffeine there is in everyday household items, which is mostly unimportant.
But I had to search for a long time to find even vague trend information about gasoline prices, which are earth-changingly important.
Not surprisingly, people act a lot more religiously in debates about oil/gas and environmental trends (with almost no information) than debates about caffeine.
2007-09-09 »
Generics in C# vs. Java
Jonathon Pryor wrote a very well-thought-out article comparing Java and C# generics.
He tries hard to be fair about it, although his preference for C# is pretty clear. Anyway, it makes a good educational article in case you wanted to learn about the screwy details of generics implementation in both languages at once.
2007-09-10 »
Google Patents
I just tried out Google Patents, and it's pretty cool. You can check out the idb backup patent from dcoombs at my last company (which has been continuing to improve the technology; after I left, they finally released some of the coolest parts that we'd been working on for more than 3 years).
There's also one with my name on it: something about abstract application notation, which I worked on several years ago for a company one of my friends founded in University.
In general, I'm against the software patent system because it's pointless - I just can't believe that less great software would be written just because you couldn't patent it. And because it's pointless and takes resources and works best if lawyers write as incomprehensibly as possible, it's also inefficient and gross on any number of levels.
Venture capitalists sure do like it if you have a patent or two in your name, though.
I do like the original idea of patents: society gives people a limited time monopoly on a particular invention, but in exchange for that, they have to give society something really valuable in exchange: the knowledge of how they did it.
Google Patents is cool because it at least helps society benefit from the patent information it paid so dearly for.
Now, if only Google Translate had a "legalese to English" button.
2007-09-11 »
A browser is part of the operating system?
Back in 1998, we hated Microsoft for saying a web browser was a critical part of an operating system.
Now an operating system without a built-in web browser would be crazy. How would you download Firefox?
2007-09-12 »
Joel Spolsky in Kitchener/Waterloo and Toronto
For anyone who didn't already know, the infamous Joel will be in Kitchener/Waterloo and then Toronto doing presentations about Fogbugz 6 and software management and things.
My timing is off, as usual - I'll be in Montreal at the time. But if you're in the area, you should go. Joel is awesome, and Fogbugz is awesome. And Fogbugz 6 might be even better.
2007-09-13 »
"Extortionist Database Architecture"
For some time now I've been talking about how the whole world of database/business/financial software is incredibly messed up. The whole system is just a morass of consultants trying to sell you crappy software that will end up costing you 10x as much in consulting fees.
But apparently there's a term for this: "Extortionist Database Architecture." Check out an interview with Vivek Ranadive of Tibco where he talks about it.
The first part of the article is really great - it frames the problem perfectly - but the rest descends into marketese. It mostly tries to sell us SOA as the answer to everything, which seems to me to be, er, unlikely. (The article is sponsored by Sun.)
The Harrah's example is especially evil, because the hard part of implementing the story he describes isn't the software at all; it's deciding which triggers should cause which reactions. If you could do that, you could build it on just about any architecture.
In other silver-bullet related news...
Improve your database performance 10x with our new database architecture! We use the highly innovative technique of storing data in columns instead of rows, resulting in a massive speed increase!
How can you go wrong? <bonk>
2007-09-15 »
Bus bathroom design
Today, a quick note that combines two of my favourite topics: bathrooms and user interface design.
I recently ended up travelling by bus from London (Ontario) to Toronto. For various reasons, I also had the chance to use the washroom on this bus.
The washroom had a great UI innovation: when you lock the door, the light comes on. Why is that so great? Well, think about it like this:
- You never want to use the washroom in the dark.(*)
- You never want to use the washroom with the door unlocked.
- It's hard to tell sometimes whether you have the door locked.
- It's easy to tell whether you have the lights on.
- It's hard to remember to turn off the lights when you're done.
- It's easy to remember to unlock the door when you're done.
This simple design innovation feels great. You go into the washroom: oh, great, another screwy industrial bathroom door lock design. I wonder how I lock it. Let's see... click - and the light turns on! It's really satisfying, because the user gets instant feedback that they have accomplished what they wanted. Even though you weren't even trying (yet) to turn on the light, the fact that it turns on is an instantly understandable signal that you have made something happen, and since you were obviously fiddling with the door lock, you can easily assume that what you made happen was the locking of the door.
Side note
Actually, there's a tiny little night-light thing that makes it possible to see even when the light is off. This serves two purposes: on your way in, you don't get obsessed with turning on the light (which would be frustrating, since there's no light switch). On the way out, you can unlock the door without immersing yourself in total darkness.
Smart!
Footnote
(*) In Spain, almost all washrooms seem to have motion-sensitive lights. Basically, this means that if you want light, you have to wave your hands around occasionally while you poo. While traveling there I developed a love-hate relationship with these motion sensors. Briefly: lights that turn themselves on and off based on a vague concept like "motion speed beyond a fixed threshold" and "no motion for a fixed amount of time" are exactly the opposite of delightfully immediate user feedback. And secondly, pooing in the dark is an interesting experience that in many cases beats waving your hands around every 30 seconds.
2007-09-17 »
Because otherwise you won't know when it's done starting
I was just searching for something else and ran into a discussion in wlach's blog from awhile ago. I replied to it at the time but it's worth reposting here, since I think it's useful information.
The question was, basically: why do daemons fork themselves into the background, anyway? It's so easy in Unix to do it yourself (by adding an & sign after the command) but very hard to force a self-backgrounding program into the foreground.
pmccurdy responded by linking to an article that may or may not have been written by djb (of qmail/djbdns fame) saying that self-backgrounding daemons are wrong, and explaining why. It's a good article.
But it doesn't actually answer the question. The real question is: why would incredibly smart people, like the original designers of Unix, have made daemons fork automatically into the background when it's so annoying and besides, they also invented inittab and inetd which do the right thing?
The answer is that when you background a subprocess yourself, you don't know when it's "done starting." For example, if I'm starting syslogd, I don't actually want to move on to the next program (which might require syslogd's socket to be listening because it sends log messages) until syslogd is actually ready to receive connections, which is later than when it's simply been forked off. If you background the process yourself, there's no way for you to know... except polling for the socket, which is gross.
So the original Unix designers actually did a really clever thing: they had the daemon fork() itself after binding the socket, so when syslogd goes into the background, you know it's ready to receive connections.
Incidentally, this is intimately related to a question that was asked around the same time on wvstreams-devel about wvfork()'s "strange" delays in the parent process. Unlike fork(), the wvfork() in WvStreams can suspend the parent process until the child has finished setting itself up - for example, listening on some sockets or closing other ones. With wvfork(), the parent does the backgrounding (as it should be) but the child can still notify the parent that it's ready (as it should be), so you get the best of both worlds... except you have to use the non-standard wvfork().
Someone also mentioned that KDE programs auto-background themselves on startup, which seems ridiculous since they're not even daemons. That's considerably more crazy, but it was also done for a good reason. The reason, as I understand it, is that to improve shared memory usage and speed (ie. data structure initialization, not .so files themselves) they actually ask the 'kdeinit' program to fork itself and load and run the library corresponding to their program. After that happens, the program you ran isn't actually doing anything, so it quits. But if kdeinit isn't running on your system, the program (a bit confusingly) doesn't fork into the background because it doesn't need to. Try it and see!
2007-09-18 »
Newflash: people can't do statistics
My two recent articles about climate change vs. objectivity and expensive gasoline got some rather more vigorous responses than what I'm used to.
The scariest responses I received were of the form, "panels of experts have analyzed the evidence, and they know a lot more about it than you or I do, so we should trust them."
Well, panels of experts have analyzed a lot of things. Here's a few experts who analyzed a huge set of scientific papers and found that most scientific papers are wrong. They hypothesize that this is because the people writing the papers are desperate to show that their work has uncovered something meaningful, so they twiddle with the statistics until they can discover something that seems mathematically significant.
Now ask yourself: if the most important assignment of your entire career was to determine, based on non-repeatable experimental observations (sensor readings over the last 100 years), whether global warming was real or not, and whether it was caused by humans or not... how honest would you be with yourself about the significance of your results?
Programmers have it easy. We may not know much either, but at least we know for sure that our trends don't follow 1000-year cycles.
2007-09-19 »
The three banking programmer virtues
Larry Wall, the designer of perl, says that the three great programmer virtues are laziness, impatience, and hubris. (Oddly, the top google hit for "programmer virtues" is on open.nit.ca. I'm honoured, but that's not actually a very good link. Use this one instead.)
While talking to dfcarney today, I was trying (again) to explain the difference between the kind of programmers I'm used to dealing with - let's call them "hackers" - and the kind of programmers that made the banking software at Pacific & Western Bank, which is where the initial Versabanq products come from.
Most programmers and most software companies, whether banking-related or not, are crud. That's because 90% of everything is crud. Let's discard that 90% for now.
The banking programmers I'm talking about are actually good at what they do. But they're also nothing like the "hackers" I'm used to dealing with. It occurred to me today that this is because the things that make you successful at writing business software are the antithesis of the three programmer virtues. Business software developers don't have laziness, impatience, and hubris, they have diligence, patience, and humility.(1)
Laziness is about finding an efficient way to do something so you don't have to do it over and over. But business rules are complicated (being invented by politicians), and often a generalization is harder to understand and maintain than a simple enumeration of the details. Instead of being lazy and thus more efficient, you're diligent and thus more precise.
Impatience is about wanting the right solution right now, and getting annoyed when the computer is being too lazy to give it to you. But most successful businesses, to the dismay of Web 2.0 companies everywhere, are slow and boring and conservative - and patient. For a bank, doing the wrong thing right now would be deadly; patiently doing the right thing in five years will make you such huge profits that it'll be worth the wait.
Hubris is about believing you can do a better job than everybody else, and thus being willing to take the risk of doing things differently in the hopes of doing them better. But financial systems are complicated, and programmers rarely have the expertise to define those systems by themselves. They need to have the humility to admit that actually, in business software, most of the time it's someone else who has the answer.
Thinking of it this way, you can begin to see why so much excellent genius-powered software is terrible for business, and why so much useful business software seems to be so inefficient.
It's a classic compromise situation, and you know how much I hate those.
In fact, it might be the most important compromise in all of computer programming. Wouldn't it be cool if there were a solution?
Absurd Footnote
(1) I did a search for these terms to see what came up. How ironic: Larry Wall's second state of the onion speech mentions exactly these three terms as the "virtues of community." I'm not sure how that ties in to what I'm saying here, but it probably does.
2007-09-22 »
SetUp/TearDown methods in unit tests are apparently considered bad now
Xunit, a replacement for Nunit (the .NET unit testing library) was just announced. It's actually done by one of the original designers of Nunit, so it's worth paying attention.
Among other design considerations, it removes support for the [SetUp] and [TearDown] tags, forcing you to do all your test initialization at the top of each test, and all your test cleanup at the bottom. (This isn't actually so bad, because if you can just encapsulate it in a single function and call that function.)
I find this interesting because I've always had a bad feeling about SetUp/TearDown, but I never knew why. WvTest (our C++ unit testing framework) supports no such thing, and I never once missed it when writing tests. But I thought maybe I was just missing something.
Now that someone else has implemented the feature and learned the hard way not to use it, they can explain the actual problems: first, if your test function doesn't call the SetUp function itself, you have to go looking elsewhere to see if there is one and what it does; and second, the one-universal SetUp function tends to become a kitchen sink of all the setup you need for all your tests, so even simple tests end up running an overly complex SetUp function, creating things they don't need and masking the simplicity of the test itself. The solution is simple: just remove that feature from the test framework, and suddenly your problems are gone! And if you really want a SetUp() function, one explicit call at the top of each test isn't a lot of typing, and it's much more clear.
Interestingly, the only testrunner in Xunit is a command-line one - just like WvTest (oddly, the command line is the one that seems to be missing in recent versions of Nunit - or maybe it's just hidden away somewhere). The importance of command-line testing was strikingly obvious to me from the beginning. How can you run your tests automatically in the autobuilder if they need you to click a GUI button?
Now I just need to wait for them to adopt the last of my WvTest innovations, which I actually just stole from perl's self-test framework. Print every assertion as it runs, don't just do a report at the end. This makes it easier to see in detail what's going on, but it also means that you can build a basic "GUI testrunner" by just running the command-line testrunner and piping it to a program that counts and filters the results. WvTest has such a filter written in tcl/tk, so when I said above that "the only testrunner is a command-line one" I lied a bit) . And the GUI testrunner will work with any program that produces output in WvTest format!
(Perl, incidentally, just has a simple filter that converts the verbose test output to a series of "." characters, which is the text-mode equivalent of a completion bar. If any test fails, you can re-run it and see its output, but in the expected end-user case where all the tests pass, it just gives a pretty summary.)
In any case, it looks like Xunit will be a good choice for a unit testing framework for our .Net work, where WvTest doesn't exist. We had recently ditched Nunit because it was too bloated and complex. Xunit has less stuff - perfect!
2007-09-28 »
If I ever need to apply for a job, this will be my cover letter
Dave,
Saw this resume last week and he looks perfect for your department. He's got expertise in all kinds of software development as well as a specialization in social engineering. We've totally got to bring him in for an interview!
-- Steve
Why would you follow me on twitter? Use RSS.