
2008-03-19 »
A tale of five merges: cvs, svn, git, darcs, etc. (Part 1: CVS)
Recently I've been experimenting a lot with software version control (and other things) using git. One of the things that's different about git vs other systems is its concept(1) of branch merging.
Put simply, the result of merging two(2) branches should be a single branch which "contains all the changes from both branches." But that definition is overly simplistic. Every version control system can do that much. The really interesting questions are (A) how automatic is it, (B) what happens to the change history, (C) what happens when you merge back and forth multiple times between two(2) branches, and (D) what happens when you "cherry pick" individual changes, usually bugfixes, from one branch to another.
Let me take you on a tour of some different merging systems to see how they differ in approaching those four questions. I won't try to say which is better, because I'm still trying to figure that out for myself :) Think of this as just a technology overview.
Today I'll tell you about CVS, which I used for years. It's completely obsolete now (at the very least you should use Subversion, which has a strict superset of CVS's features), but it's instructional, because to do branching and merging in CVS, you really have to understand what you're doing. This understanding will come in handy when we discuss the other systems later.
CVS merging
Despite what you may have heard, CVS has perfectly good support for merging changes between branches, and even for bi-directional merges back and forth between branches. People who claim that CVS cannot do these things are simply boneheads.(3)
"But!" you say. "But CVS doesn't even have a merge command! How can it possibly claim to support merging?" If you say this, then you, too, are a bonehead. CVS doesn't have a command called "merge", but it does have "cvs up -j", the description (from "cvs --help up") of which is "Merge in changes made between current revision and rev."
"But!" you interrupt again. "But CVS doesn't even have atomic commits! How can you be sure what you've merged?" This is true, but if you think this actually matters, there are some things you don't know. Remember, CVS locks the entire repository during a commit, so commits are "atomic" in that sense. What people say when they say CVS doesn't have "atomic commits" is actually that each file has its own history (and revision numbers!), so sometimes it's hard to tell which files were involved in a particular checkin. That's very true, and it's annoying, but it has no impact on our ability to do branching and merging. Why? Because CVS has perfectly good tagging. You can tag every file in your checked-out repository at a particular time, and that tag will end up only in the exact revisions that you had checked out at that time. A CVS tag is a perfectly reliable marker of repository state as it existed at a particular point in time.(4)
The upshot of all this is that if you're going to do merges with CVS, you do it by using the little-known "cvs up -j BEFORE -j AFTER" command, where BEFORE and AFTER are tags.
Ah, but which tags should you use for BEFORE and AFTER? Well, the tag you created BEFORE you made your changes, and the tag you created AFTER you made your changes, respectively. "cvs up -j -j" merges all the changes from BEFORE to AFTER into the branch you currently have checked out. Then you fix your conflicts and check in the merged branch.
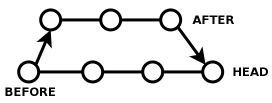
Note that when you've done this, you still have two branches, which I'll call AFTER and HEAD. HEAD contains all the changes from the branch you were originally on, plus the changes between BEFORE and AFTER. AFTER just contains the changes from BEFORE to AFTER, but nothing else that has been happening in HEAD.
CVS multiple merges
So what if work continues on the AFTER branch and you want to merge those changes into HEAD? Oh no, "cvs up -j BEFORE -j AFTER" won't work, because it'll try to merge some of the same changes as last time, and cause a zillion conflicts!
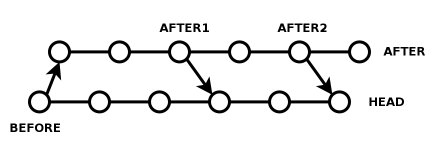
Well, don't do that then. Instead, keep your old AFTER tag and call it AFTER1. Check in more stuff to the AFTER branch, and when you're ready to merge, call it AFTER2. Then just do "cvs up -j AFTER1 -j AFTER2". No conflicts. It's easy, once you get the hang of it.
CVS bidirectional merges
"Aha," you say. "I've got you now! But what if I want to then merge the changes in HEAD back into my AFTER branch, then continue working on my AFTER branch, and then merge my AFTER changes back into HEAD? Bwahaha!"
This sounds complicated enough to make your head spin, but actually it's not hard at all once you understand it.
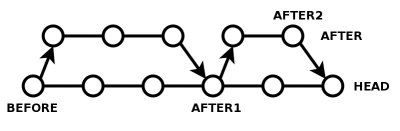
The critical realization is: merging all the changes from HEAD into AFTER, and merging all the changes from AFTER into HEAD, is a trick question. Actually, both operations are the same. The merge you did above has produced an AFTER+HEAD combined branch, so if that's what you want, just make a tag called AFTER1 pointing to HEAD, point your AFTER branch at AFTER1, and keep working in AFTER. Next time you need to merge in one direction or the other, AFTER1 is always the starting branch. You either do "cvs up -j AFTER1 -j AFTER2" in HEAD, or you do "cvs up -j AFTER1 -j HEAD" in AFTER2. In both cases, you don't get any unnecessary conflicts.
I know, your head is probably spinning at this point, but relax. At the very least, the only commands you had to learn were "cvs tag" and "cvs up". And CVS is totally obsolete right now, so you'll never have to do this yourself. CVS-style tagging merging is just interesting because it's the basis for everything else.(5)
To summarize, all merging in CVS is a simple matter of these steps:
- Tag the branchpoint (the point where two branches diverge) as BEFORE.
- Make changes.
- Make a tag called AFTER after your changes.
- Check out the destination branch called HEAD.
- Merge your changes into the destination with "cvs up -j BEFORE -j AFTER".
- Repeat as necessary.
CVS overall
Okay, now we're ready to quickly answer our original questions.
CVS: (A) is not very automatic at all, and slow and error prone to boot; (B) makes it really hard to get change history except on the HEAD branch, so you have to track it all by hand; (C) supports back-and-forth merges with no more trouble than single merges; and (D) has terrible support for cherry picking since you probably didn't bother to make a tag for every single checkin, and without tags, CVS merging is impossible.
Next time: merging in Subversion.
Footnotes
(1) Note that I'm not talking about merge algorithms here. Discussions about that tend to lead to flamewars, but aren't really the important part. Everyone intuitively agrees what the outcome of branch merging should be. The flamewars are never about the outcome, they're about the algorithm used to achieve that outcome.
(2) Git happens to be able to merge two or more branches at once, but that's a straightforward extension of the merging concept. Let's just talk about two of them for simplicity.
(3) Here is my argument that CVS and SVN can happily do bi-directional merges: I've done it repeatedly in production settings with dozens of developers, therefore it is possible. QED. Now, you go try to prove that it can't be done. Come back when your argument is more convincing than mine. Thank you.
(4) Note that a subversion "revision number" is functionally exactly equivalent to a cvs tag, except that it doesn't have a human-readable name, it gets created automatically with every checkin, and subversion creates tags in O(1) time while CVS does not.
(5) Yes, even (gasp!) git. But don't tell Linus.
Update 2008/03/20: Some people just complain when your article is too complicated. But cpirate sends you diagrams (which I have now inserted above). Thanks, Peter!
Why would you follow me on twitter? Use RSS.