
2018-08-08 »
A little bump in the wire that makes your Internet faster
My parents live in a rural area, where the usual monopolist Internet service provider provides the usual monopolist Internet service: DSL, really far from the exchange point, very very asymmetric, and with insanely oversized buffers (ie. bufferbloat), especially in the upstream direction. The result is that, basically, if you tried to browse the web while uploading anything, it pretty much didn't work at all.
I wrote about the causes of these problems (software, of course) in my bufferbloat rant from 2011. For some reason, there's been a recent resurgence of interest in that article. Upon rereading it, I (re-)discovered that it's very... uh... stream-of-consciousness. I find it interesting that some people like it so much. Even I barely understand what I wrote anymore. Also, it's now obsolete, because there are much better solutions to the problems than there used to be, so even people who understand it are not going to get the best possible results. Time for an update!
The Challenge
I don't live in the same city as my parents, and I won't be back for a few months, but I did find myself with some spare time and a desire to pre-emptively make their Internet connection more usable for next time I visited. So, I wanted to build a device (a "bump in the wire") that:
- Needs zero configuration at install time
- Does not interfere with the existing network (no DHCP, firewall, double NAT, etc)
- Doesn't reduce security (no new admin ports in the data path)
- Doesn't need periodic reboots
- Actually solves their bufferbloat problem
Let me ruin the surprise: it works. Although we'll have to clarify "works" a bit.
If you don't care about all that, skip down to the actual setup down below.
This is an improvement, I promise!
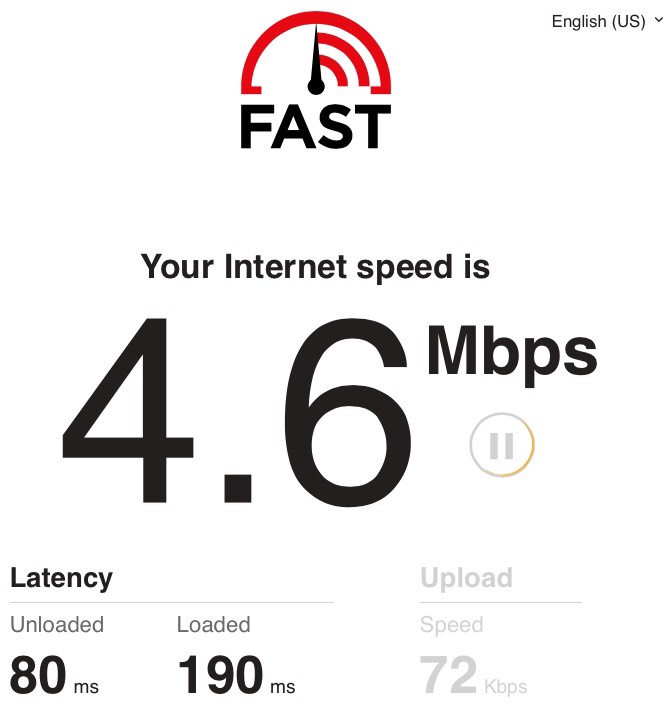
Here's the fast.com test result before we installed the Bump.
(Side note: there are a lot of speedtests out there. I like fast.com for two reasons. First, they have an easy-to-understand bufferbloat test. Second, their owner has strong incentives to test actual Internet speeds including peering, and to bypass various monopolistic ISPs' various speedtest-cheating traffic shaping techniques.)
And here's what it looked like after we added the Bump:
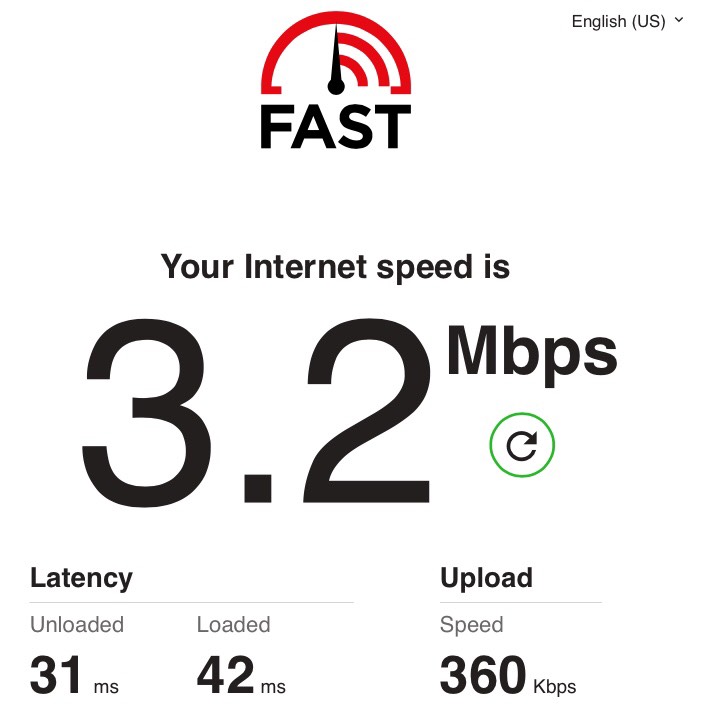
...okay, so you're probably thinking, hey, that big number is lower now! It got worse! Yes. In a very narrow sense, it did get worse. But in most senses (including all the numbers in smaller print), it got better. And even the big number is not as much worse as it appears at first.
It would take a really long time and a lot of words to try to explain how these numbers interact and why it matters. But unluckily for you, I'm on vacation!
Download speed is the wrong measurement
In my wifi data
presentation from 2016, I spent a lot of time exploring what makes an
Internet connection feel "fast." In particular, I showed a slide
from an FCC report from 2015 (back when the FCC was temporarily
anti-monopolist): 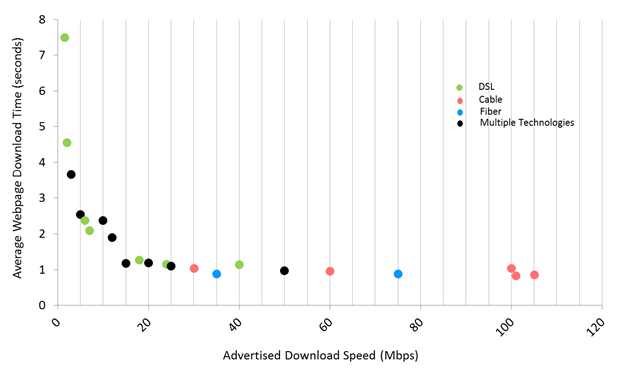
What's that slide saying? Basically, that beyond 20 Mbps or so, typical web page load times stop improving.1 Sure, if you're downloading large files, a faster connection will make it finish sooner.2 But most people spend most of their time just browsing, not downloading.
Web page load times are limited by things other than bandwidth, including javascript parsing time, rendering time, and (most relevant to us here) round trip times to the server. (Most people use "lag", "latency", and "round trip time" to mean about the same thing, so we'll do that here too.) Loading a typical web page requires several round trips: to one or more DNS servers, then the TCP three-way handshake, then SSL negotiation, then grabbing the HTML, then grabbing the javascript it points to, then grabbing whatever other files are requested by the HTML and javascript. If that's, say, 10 round trips, at 100ms each, you can see how a typical page would take at least a second to load, even with no bandwidth constraints. (Maybe there are fewer round trips needed, each with lower latencies; same idea.)
So that's the first secret: if your page load times are limited by round trip time, and round trip time goes from 80ms (or 190ms) to 31ms (or 42ms), then you could see a 2x (or 4.5x) improvement in page load speed, just from cutting latency. Our Bump achieved that - which I'll explain in a moment.
It also managed to improve the measured uplink speed in this test. How is that possible? Well, probably several interconnected reasons, but a major one is: TCP takes longer to get up to speed when the round trip time is longer. (One algorithm for this is called TCP slow start.) And it has even more trouble converging if the round trip time is variable, like it was in the first test above. The Bump makes round trip time lower, but also more consistent, so it improves TCP performance in both ways.
But how does it work?
Alert readers will have noticed that by adding a Bump in the wire, that is, by adding an extra box and thus extra overhead, I have managed to make latency less. Alert readers will hate this, as they should, because it's called "negative latency," and alert readers know that there is no such thing. (I tried to find a good explanation of it on the web, but all the pages I could find sucked. I guess that's fair, for a concept that does not exist. Shameless self-plug then: I did write a fun article involving this topic back in 2009 about work we did back in 2003. Apparently I've been obsessing over this for a long time.)
So, right, the impossible. As usual, the impossible is a magic trick. Our Bump doesn't subtract latency; it just tricks another device - in this case the misconfigured DSL router provided by the monopolistic ISP - into adding less latency, by precisely adding a bit of its own. The net result is less than the DSL router on its own.
Bufferbloat (and chocolate)
Stop me if you've heard this one before. Most DSL routers and cable modems have buffers that were sized to achieve the maximum steady-state throughput on a very fast connection - the one that the monopolistic ISP benchmarks on, for its highest priced plan. To max out the speed in such a case, you need a buffer some multiple of the "bandwidth delay product," (BDP) which is an easier concept than it sounds like: just multiply the bandwidth by the round trip time (delay). So if you have 100ms round trip time and your upstream is about 25 Mbps = ~2.5 MBytes/sec, then your BDP is 2.5 Mbytes/sec * 0.1sec = 2.5 MBytes. If you think about it, the BDP is "how much data fits in the wire," the same way a pipe's capacity is how much water fits in the pipe. For example, if a pipe spits out 1L of water per second, and it takes 10 seconds for water to traverse the pipe, then the pipe contains 1L x 10 seconds = 10L.
Anyway, the pipe is the Internet3, and we can't control the bandwidth-delay product of the Internet from our end. People spend a lot of time trying to optimize that, but they get paid a lot, and I'm on vacation, and they don't let me fiddle with their million-dollar equipment, so too bad. What I can control is the equipment that feeds into the pipe: my router, or, in our plumbing analogy, the drain.

Duck in a bathtub drain vortex,
via pinterest
You know how when you drain the bathtub, near the end it starts making that sqlrshplshhh sucking noise? That's the sound of a pipe that's not completely full. Now, after a nice bath that sound is a key part of the experience and honestly makes me feel disproportionately gleeful, but it also means your drain is underutilized. Err, which I guess is a good thing for the environment. Uh.
Okay, new analogy: oil pipelines! Wait, those are unfashionable now too. Uh... beer taps... no, apparently beer is bad for diversity or something... chocolate fountains!

Chocolate fountain via indiamart
Okay! Let's say you rented one of those super fun chocolate fountain machines for a party: the ones where a pool of delicious liquid chocolate goes down a drain at the bottom, and then gets pumped back up to the top, only to trickle gloriously down a chocolate waterfall (under which you can bathe various fruits or whatever) and back into the pool, forever, until the party is over and the lucky, lucky party consultants get to take it home every night to their now-very-diabetic children.
Mmmm, tasty, tasty chocolate. What were we talking about again?
Oh right. The drain+pump is the Internet. The pool at the bottom is the buffer in your DSL router. And the party consultant is, uh, me, increasingly sure that I've ended up on the wrong side of this analogy, because you can't eat bits, and now I'm hungry.
Aaaaanyway, a little known fact about these chocolate fountain machines is that they stop dripping chocolate before the pool completely empties. In order to keep the pump running at capacity, there needs to be enough chocolate in the pool to keep it fully fed. In an ideal world, the chocolate would drip into the pool and then the pump at a perfectly constant rate, so you could adjust the total amount of chocolate in the system to keep the pool+pump content at the absolute minimimum, which is the bandwidth-delay product (FINALLY HE IS BACK ON TOPIC). But that would require your chocolate to be far too watery; thicker chocolate is more delicious (SIGH), but has the annoying habit of dripping in clumps (as shown in the picture) and not running smoothly into the drain unless the pool has extra chocolate to push it along. So what we do is to make the chocolate thicker and clumpier (not negotiable) and so, to keep the machine running smoothly, we have to add extra chocolate so that the pool stays filled, and our children thus become more diabetic than would otherwise be necessary.
Getting back to the math of the situation, if you could guarantee perfectly smooth chocolate (packet) flow, the capacity of the system could be the bandwidth-delay product, which is the minimum you need in order to keep the chocolate (bits) dripping at the maximum speed. If you make a taller chocolate tower (increase the delay), you need more chocolate, because the BDP increases. If you supersize your choco-pump (get a faster link), it moves the chocolate faster, so you need more chocolate, because the BDP increases. And if your chocolate is more gloppy (bursty traffic), you need more chocolate (bits of buffer) to make sure the pump is always running smoothly.
Moving back into pure networking (FINALLY), we have very little control over the burstiness of traffic. We generally assume it follows some statistical distribution, but in any case, while there's an average flow rate, the flow rate will always fluctuate, and sometimes it fluctuates by a lot. That means you might receive very little traffic for a while (draining your buffer aka chocolate pool) or you might get a big burst of traffic all at once (flooding your buffer aka chocolate pool). Because of a phenomenon called self-similarity, you will often get the big bursts near the droughts, which means your pool will tend to fill up and empty out, or vice versa.
(Another common analogy for network traffic is road traffic. When a road is really busy, car traffic naturally arranges itself into bursts, just like network traffic does.)
Okay! So your router is going to receive bursts of traffic, and the amount of data in transit will fluctuate. To keep your uplink fully utilized, there must always be 1 BDP of traffic in the Internet link (the round trip from your router to whatever server and back). To fill the Internet uplink, you need to have a transmit queue in the router with packets. Because the packets arrive in bursts, you need to keep that transmit queue nonempty: there's an ideal fill level so that it (almost) never empties out, but so our children don't get unnecessarily diabetic, um, I mean, so that our traffic is not unnecessarily delayed.
An empty queue isn't our only concern: the router has limited memory. If the queue memory fills up because of a really large incoming burst, then the only thing we can do is throw away packets, either the newly-arrived ones ("tail drop") or some of the older ones ("head drop" or more generally, "active queue management").
When we throw away packets, TCP slows down. When TCP slows down, you get slower speedtest results. When you get slower speedtest results, and you're a DSL modem salesperson, you sell fewer DSL modems. So what do we do? We add more RAM to DSL modems so hopefully the queue never fills up.4 The DSL vendors who don't do this, get a few percent slower speeds in the benchmarks, so nobody buys their DSL modem. Survival of the fittest!
...except, as we established earlier, that's the wrong benchmark. If customers would time page load times instead of raw download speeds, shorter buffers would be better. But they don't, unless they're the FCC in 2015, and we pay the price. (By the way, if you're an ISP, use better benchmarks! Seriously.)
So okay, that's the (very long) story of what went wrong. That's "bufferbloat." How do we fix it?
"Active" queue management
Imagine for a moment that we're making DSL routers, and we want the best of both worlds: an "unlimited" queue so it never gets so full we have to drop packets, and the shortest possible latency. (Now we're in the realm of pure fiction, because real DSL router makers clearly don't care about the latter, but bear with me for now. We'll get back to reality later.)
What we want is to have lots of space in the queue - so that when a really big burst happens, we don't have to drop packets - but for the steady state length of the queue to be really short.
But that raises a question. Where does the steady state length of the queue come from? We know why a queue can't be mainly empty - because we wouldn't have enough packets to keep the pipe full - and we know that the ideal queue utilization has something to do with the BDP and the burstiness. But who controls the rate of incoming traffic into the router?
The answer: nobody, directly. The Internet uses a very weird distributed algorithm (or family of algorithms) called "TCP congestion control." The most common TCP congestion controls (Reno and CUBIC) will basically just keep sending faster and faster until packets start getting dropped. Dropped packets, the thinking goes, mean that there isn't enough capacity so we'd better slow down. (This is why, as I mentioned above, TCP slows down when packets get dropped. It's designed that way.)
Unfortunately, a side effect of this behaviour is that the obvious dumb queue implementation - FIFO - will always be full. That's because the obvious dumb router doesn't drop packets until the queue is full. TCP doesn't slow down until packets are dropped,5 so it doesn't slow down until the queue is full. If the queue is not full, TCP will speed up until packets get dropped.6
So, all these TCP streams are sending as fast as they can until packets get dropped, and that means our queue fills up. What can we do? Well, perversely... we can drop packets before our queue fills up. As far as I know, the first proposal of this idea was Random Early Detection (RED), by Sally Floyd and Van Jacobson. The idea here is that we calculate the ideal queue utilization (based on throughput and burstiness), then drop more packets if we exceed that length, and fewer packets if we're below that length.
The only catch is that it's super hard to calculate the ideal queue utilization. RED works great if you know that value, but nobody ever does. I think I heard that Van Jacobson later proved that it's impossible to know that value, which explains a lot. Anyway, this led to the development of Controlled Delay (CoDel), by Kathleen Nichols and Van Jacobson. Instead of trying to figure out the ideal queue size in packets, CoDel just sees how long it takes for packets to traverse the queue. If it consistently takes "too long," then it starts dropping packets, which signals TCP to slow down, which shortens the average queue length, which means a shorter delay. The cool thing about this design is it's nearly configuration-free: "too long," in milliseconds, is pretty well defined no matter how fast your link is. (Note: CoDel has a lot of details I'm skipping over here. Read the research paper if you care.)
Anyway, sure enough, CoDel really works, and you don't need to configure it. It produces the best of both worlds: typically short queues that can absorb bursts. Which is why it's so annoying that DSL routers still don't use it. Jerks. Seriously.
Flow queueing (FQ)
A discussion on queue management wouldn't be complete without a discussion about flow queueing (FQ), the second half of the now very popular (except among DSL router vendors) fq_codel magic combination.
CoDel is a very exciting invention that should be in approximately every router, because it can be implemented in hardware, requires almost no extra memory, and is very fast. But it does have some limitations: it takes a while to converge, and it's not really "fair"7. Burstiness in one stream (or ten streams) can increase latency for another, which kinda sucks.
Imagine, for example, that I have an ssh session running. It uses almost no bandwidth: most of the time it just goes as fast as I can type, and no faster. But I'm also running some big file transfers, both upload and download, and that results in an upload queue that has something to do with the BDP and burstiness of the traffic, which could build up to hundreds of extra milliseconds. If the big file transfers weren't happening, my queue would be completely empty, which means my ssh traffic would get through right away, which would be optimal (just the round trip time, with no queue delay).
A naive way to work around this is prioritization: whenever an ssh packet arrives, put it at the front of the queue, and whenever a "bulk data" packet arrives, put it at the end of the queue. That way, ssh never has to wait. There are a few problems with that method though. For example, if I use scp to copy a large file over my ssh session, then that file transfer takes precedence over everything else. Oops. If I use ssh on a different port, there's no way to tag it. And so on. It's very brittle.
FQ tries to give you (nearly) the same low latency, even on a busy link, with no special configuration. To make a long story short, it keeps a separate queue for every active flow (or stream), then alternates "fairly"7 between them. Simple round-robin would work pretty well, but they take it one step further, detecting so-called "fat" flows (which send as fast as they can) and "thin" flows (which send slower than they can) and giving higher priority to the thin ones. An interactive ssh session is a thin flow; an scp-over-ssh file transfer is a fat flow.
And then you put CoDel on each of the separate FQ queues, and you get Linux's fq_codel, which works really well.
Incidentally, it turns out that FQ alone - forget about CoDel or any other active queue management - gets you most of the benefits of CoDel, plus more. You have really long queues for your fat flows, but the thin flows don't care. The CoDel part still helps (for example, if you're doing a videoconference, you really want the latency inside that one video stream to be as low as possible; and TCP always works better with lower latency), and it's cheap, so we include it. But FQ has very straightforward benefits that are hard to resist, as long as you and FQ agree on what "fairness"7 means.
FQ is a lot more expensive than CoDel: it requires you to maintain more queues - which costs more memory and CPU time and thrashes the cache more - and you have to screw around with hash table algorithms, and so on. As far as I know, nobody knows how to implement FQ in hardware, so it's not really appropriate for routers running at the limit of their hardware capacity. This includes super-cheap home routers running gigabit ports, or backbone routers pushing terabits. On the other hand, if you're limited mainly by wifi (typically much less than a gigabit) or a super slow DSL link, the benefits of FQ outweigh its costs.8
Back to the Bump
Ok, after all that discussion about CoDel and FQ and fq_codel, you might have forgotten that this whole exercise hinged on the idea that we were making DSL routers, which we aren't, but if we were, we could really cut down that latency. Yay! Except that's not us, it's some hypothetical competent DSL router manufacturer.
I bet you're starting to guess what the Bump is, though, right? You insert it between your DSL modem and your LAN, and it runs fq_codel, and it fixes all the queuing, and life is grand, right?
Well, almost. The problem is, the Bump has two ethernet ports, the LAN side and the WAN side, and they're both really fast (in my case, 100 Mbps ethernet, but they could be gigabit ethernet, or whatever). So the data comes in at 100 Mbps, gets enqueued, then gets dequeued at 100 Mbps. If you think about it for a while, you'll see this means the queue length is always 0 or 1, which is... really short. No bufferbloat there, which means CoDel won't work, and no queue at all, which means there's nothing for FQ to prioritize either.
What went wrong? Well, we're missing one trick. We have to release the packets out the WAN port (toward the DSL modem) more slowly. Ideally, we want to let them out perfectly smoothly at exactly the rate that the DSL modem can transmit them over the DSL link. This will allow the packets to enqueue in the Bump instead, where we can fq_codel them, and will leave the DSL modem's dumb queue nearly empty. (Why can that queue be empty without sacrificing DSL link utilization? Because the burstiness going into the DSL modem is near zero, thanks to our smooth release of packets from the Bump. Remember our chocolate fountain: if the chocolate were perfectly smooth, we wouldn't need a pool of chocolate at the bottom. There would always be exactly the right amount of chocolate to keep the pump going.)
Slowing down the packet outflow from the Bump is pretty easy using something called a token bucket filter (tbf). But it turns out that nowadays there's a new thing called "cake" which is basically fq_codel+tbf combined. Combining them has some advantages that I don't really understand, but one of them is that it's really easy to set up. You just load the cake qdisc, tell it the upload and download speeds, and it does the magic. Apparently it's also less bursty and takes less CPU. So use that.
The only catch is... what upload/download speeds should we give to cake? Okay, I cheated for that one. I just asked my dad what speed his DSL link goes in real life, and plugged those in. (Someday I want to build a system that can calculate this automatically, but... it's tricky.)
But what about the downstream?
Oh, you caught me! All that stuff was talking about the upstream direction. Admittedly, on DSL links, the upstream direction is usually the worst, because it's typically about 10x slower than the downstream, which means upstream bufferbloat problems are about 10x worse than downstream. But of course, not to be left out, the people making the big heavy multi-port DSL equipment at the ISP added plenty of bufferbloat too. Can we fix that?
Kind of. I mean, ideally they'd get a Bump over on their end, between the ISP and their DSL megarouter, which would manage the uplink's queue. Or, if we're dreaming anyway, the surprisingly competent vendor of the DSL megarouter would just include fq_codel, or at least CoDel, and they wouldn't need an extra Bump. Fat chance.
It turns out, though, that if you're crazy enough, you can almost make it work in the downstream direction. There are two catches: first, FQ is pretty much impossible (the downstream queue is just one queue, not multiple queues, so tough). And second, it's a pretty blunt instrument. What you can do is throw away packets after they've traversed the downstream queue, a process called "policing" (as in, we punish your stream for breaking the rules, rather than just "shaping" all streams so that they follow the rules). With policing, the best you can do is detect that data is coming in too fast, and start dropping packets to slow it down. Unfortunately, the CoDel trick - dropping traffic only if the queue is persistently too long - doesn't work, because on the receiving side, you don't know how big the queue is. When you get a packet from the WAN side, you just send it to the LAN side, and there's no bottleneck, so your queue is always empty. You have to resort to just throwing away packets whenever the incoming rate is even close to the maximum. That is, you have to police to a rate somewhat slower than the DSL modem's downlink speed.
Whereas in the upload direction, you could use, say, 99.9% of the upload rate and still have an empty queue on the DSL router, you don't have the precise measurements needed for that in the download direction. In my experience you have to use 80-90%.
That's why the download speed in the second fast.com test at the top of this article was reduced from the first test: I set the shaping rate pretty low. (I think I set it too low, because I wanted to ensure it would cut the latency. I had to pick some guaranteed-to-work number before shipping the Bump cross-country to my parents, and I only got one chance. More tuning would help.)
Phew!
I know, right? But, assuming you read all that, now you know how the Bump works. All that's left is learning how to build one.
BYOB (Build Your Own Bump)
Modern Linux already contains cake, which is almost all you need. So any Linux box will do, but the obvious choice is a router where you install openwrt. I used a D-Link DIR-825 because I didn't need it to go more than 100 Mbps (that's a lot faster than a 5 Mbps DSL link) and I liked the idea of a device with 0% proprietary firmware. But basically any openwrt hardware will work, as long as it has at least two ethernet ports.
You need a sufficiently new version of openwrt. I used 18.06.0. From there, install the SQM packages, as described in the openwrt wiki.
Setting up the cake queue manager
This part is really easy: once the SQM packages are installed in openwrt, you just activate them in the web console. First, enable SQM like this:
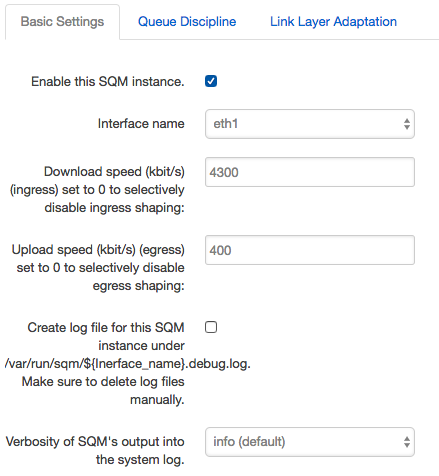
In the Queue Discipline tab, make sure you're using cake instead of whatever the overcomplicated and mostly-obsolete default is:
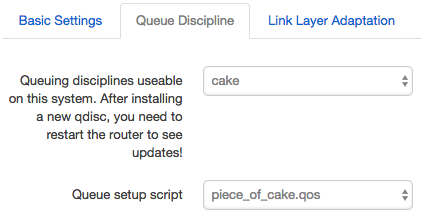
(You could mess with the Link Layer Adaptation tab, but that's mostly for benchmark twiddlers. You're unlikely to notice if you just set your download speed to about 80%, and upload speed to about 90%, of the available bandwidth. You should probably also avoid the "advanced" checkboxes. I tried them and consistently made things worse.)
If you're boring, you now have a perfectly good wifi/ethernet/NAT router that happens to have awesome queue management. Who needs a Bump? Just throw away your old wifi/router/firewall and use this instead, attached to your DSL modem.
Fancy bridge mode
...On the other hand, if, like me, you're not boring, you'll want to configure it as a bridge, so that nothing else about the destination network needs to be reconfigured when you install it. This approach just feels more magical, because you'll have a physical box that produces negative latency. It's not as cool if the negative and positive latencies are added together all in one box; that's just latency.
What I did was to configure the port marked "4" on the DIR-825 to talk to its internal network (with a DHCP server), and configure the port marked "1" to bridge directly to the WAN port. I disabled ports 2 and 3 to prevent bridging loops during installation.
To do this, I needed two VLANs, like this:
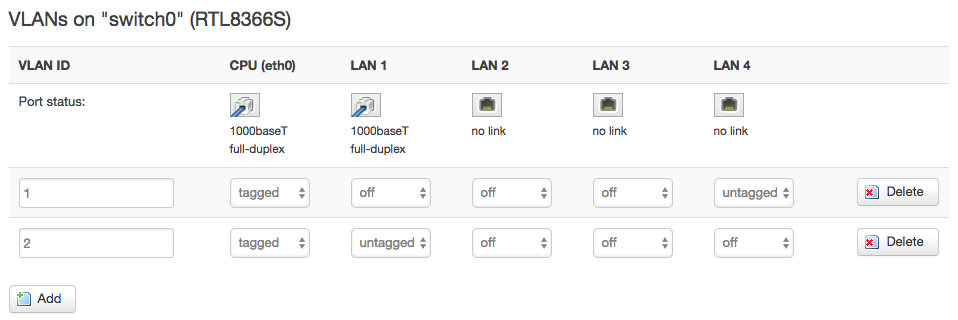
(Note: the DIR-825 labels have the ports in the opposite order from openwrt. In this screenshot, port LAN4 is on VLAN1, but that's labelled "1" on the physical hardware. I wanted to be able to say "use ports 1 and WAN" when installing, and reserve port 4 only for configuration purposes, so I chose to go by the hardware labels.)
Next, make sure VLAN2 (aka eth0.2) is not bridged to the wan port (it's the management network, only for configuring openwrt):

And finally, bridge VLAN1 (aka eth0.1) with the wan port:
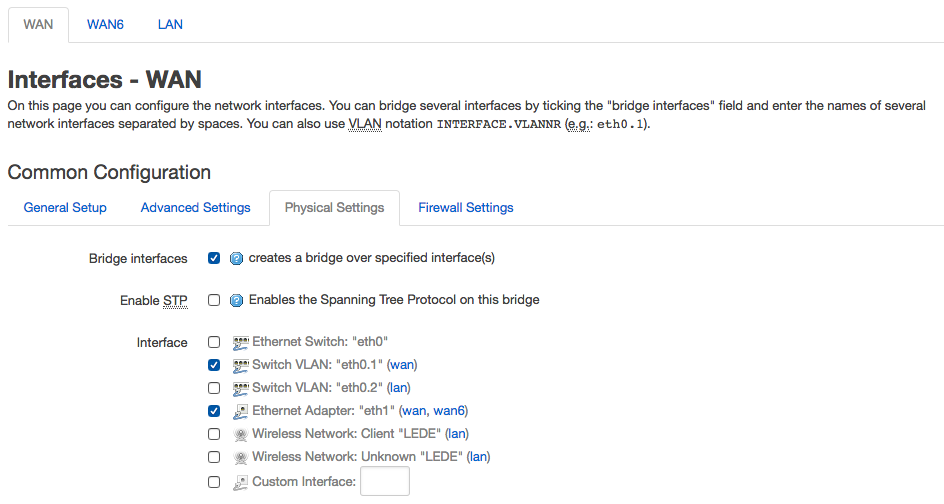
You may need to reboot to activate the new settings.
Footnotes
1 Before and since that paper in 2015, many many people have been working on cutting the number of round trips, not just the time per round trip. Some of the recent improvements include TCP fast open, TLS session resumption, and QUIC (which opens encrypted connections in "zero" round trips). And of course, javascript and rendering engines have both gotten faster, cutting the other major sources of page load times. (Meanwhile, pages have continued getting larger, sigh.) It would be interesting to see an updated version of the FCC's 2015 paper to see if the curve has changed.
2 Also, if you're watching videos, a faster connection will improve video quality (peaking at about 5 Mbps/stream for an 1080p stream or 25 Mbps/stream for 4K, in Netflix's case). But even a 20 Mbps Internet connection will let you stream four HD videos at once, which is more than most people usually need to do.
3 We like to make fun of politicians, but it's actually very accurate to describe the Internet as a "series of tubes," albeit virtual ones.
4 A more generous interpretation is that DSL modems end up with a queue size calculated using a reasonable formula, but for one particular use case, and fixed to a number of bytes. For example, a 100ms x 100 Mbps link might need 0.1s x 100 Mbit/sec x ~0.1 bytes/bit = 1 Mbyte of buffer. But on a 5 Mbit/sec link, that same 1 Mbyte would take 10 Mbits / 5 Mbit/sec = 2 seconds to empty out, which is way too long. Unfortunately, until a few years ago, nobody understood that too-large buffers could be just as destructive as too-small ones. They just figured that maxing out the buffer would max out the benchmark, and that was that.
5 Various TCP implementations try to avoid this situation. My favourite is the rather new TCP BBR, which does an almost magically good job of using all available bandwidth without filling queues. If everyone used something like BBR, we mostly wouldn't need any of the stuff in this article.
6 To be more precise, in a chain of routers, only the "bottleneck" router's queue will be full. The others all have excess capacity because the link attached to the bottleneck is overloaded. For a home Internet connection, the bottleneck is almost always the home router, so this technicality doesn't matter to our analysis.
7 Some people say that "fair" is a stupid goal in a queue. They probably say this because fairness is so hard to define: there is no queue that can be fair by all possible definitions, and no definition of fair will be the "best" thing to do in all situations. For example, let's say I'm doing a videoconference call that takes 95% of my bandwidth and my roommate wants to visit a web site. Should we now each get 50% of the bandwidth? Probably not: video calls are much more sensitive to bandwidth fluctuations, whereas when loading a web page, it mostly doesn't matter if it takes 3 seconds instead of 1 second right now, as long as it loads. I'm not going to try to take sides in this debate, except to point out that if you use FQ, the latency for most streams is much lower than if you don't, and I really like low latency.
8 Random side note: FQ is also really annoying because it makes your pings look fast even when you're building up big queues. That's because pings are "thin" and so they end up prioritized in front of your fat flows. Weirdly, this means that most benchmarks of FQ vs fq_codel show exactly the same latencies; FQ hides the CoDel improvements unless you very carefully code your benchmarks.
Why would you follow me on twitter? Use RSS.